
Introduction
Most businesses are sitting on a mountain of data they can't actually use. CRMs, ERPs, marketing platforms, spreadsheets, cloud apps—each system captures a slice of business reality, but none of them talk to each other. The result: analysts spend hours stitching data together manually, leadership makes decisions on stale numbers, and opportunities disappear into the gaps between systems.
According to MuleSoft's research, 89% of IT leaders say data silos create challenges for digital transformation—and the average enterprise runs 900 applications with only 28% integrated. That's not a reporting problem. It's an infrastructure problem.
ETL pipeline services solve it. They automate the movement and transformation of raw data from every source system into a single, analysis-ready destination, so teams spend time acting on insights rather than assembling them.
This article covers how ETL pipelines work, best practices for building reliable ones, the ETL vs. ELT decision, and how to evaluate pipeline service providers before you commit to one.
Key Takeaways
- ETL pipelines automate data movement from source systems into a destination warehouse, eliminating manual data work
- Each stage (Extract, Transform, Load) involves design decisions that directly affect pipeline reliability and performance
- ELT is the modern default for cloud-native stacks; ETL remains right for compliance-heavy or legacy-system environments
- Poor data quality costs organizations an average of $12.9M per year, making pipeline quality controls non-negotiable
- The best ETL service providers own the full lifecycle—design, build, monitoring, and ongoing maintenance
What Are ETL Pipeline Services?
ETL pipeline services are the professional design, development, and ongoing management of Extract, Transform, Load workflows. These are expert-led data engineering engagements that build and maintain the infrastructure moving data across your business — not software tools you configure yourself.
The distinction matters. Self-serve tools like Fivetran or Airbyte handle connector-level data movement well enough. What they don't provide is architectural judgment: knowing which extraction strategy fits your source system's load tolerance, or how to structure transformation logic that serves five different downstream use cases without breaking when one changes.
That kind of judgment also covers pipeline maintainability — designing systems that still make sense two years later, when the engineer who built them has moved on.
ETL pipeline services typically serve three types of organizations:
- Companies undergoing digital transformation who need reliable data infrastructure, not just another SaaS tool subscription
- Organizations scaling data operations beyond what in-house teams can manage, especially when 77% of companies report lacking the data talent needed for mission-critical data work
- Businesses consolidating data from many disparate systems for reporting, analytics, or AI workloads that require clean, structured inputs
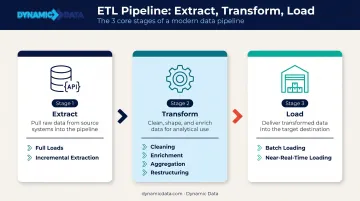
How ETL Pipelines Work: The 3 Core Stages
A pipeline moves data through three sequential stages: pull it from its origins, reshape it to meet business standards, then deliver it somewhere it can be used.
Extract
Extraction retrieves raw data from source systems—relational databases, cloud applications, REST APIs, flat files, ERP and CRM platforms, streaming data sources.
Extraction follows one of two strategies:
- Full loads pull all data every run—simple but resource-intensive, suited for smaller datasets or initial setup
- Incremental extraction retrieves only records that are new or changed since the last cycle. For production pipelines handling large volumes, this is the standard approach — it cuts processing time and reduces strain on source systems
The extraction strategy you choose affects everything downstream. Pulling full data sets on a schedule works fine at 10,000 records; it becomes a problem at 10 million.
Transform
Transformation is where raw data becomes trustworthy data. This stage covers:
- Cleaning — removing duplicates, handling null values, standardizing formats
- Enrichment — adding context from reference data or lookup tables
- Aggregation — summarizing records into meaningful metrics
- Restructuring — reshaping data to match the destination schema
The quality of transformation logic directly determines whether your downstream reports are reliable. Poor transformation decisions compound quickly. Gartner estimates bad data quality costs organizations $12.9M per year on average — most of it rooted in transformation logic that was skipped or rushed during initial pipeline development.
Load
The Load stage moves transformed data into a target system—typically a cloud data warehouse like Snowflake, BigQuery, or Redshift, or a data lake.
How data lands in the destination depends on your freshness requirements:
- Batch loading delivers large data volumes on a schedule (hourly, nightly, weekly)—appropriate for reporting workloads where freshness requirements are measured in hours
- Near-real-time loading keeps data continuously refreshed for operational use cases—dashboards where hour-old data means missed decisions
The right approach depends on how time-sensitive the downstream use case actually is. Building a near-real-time pipeline for a monthly financial report wastes engineering effort; using batch loading for a live operations dashboard defeats its purpose.
Key Best Practices for Reliable ETL Pipeline Services
Data Quality Validation at Every Stage
Validation can't live only at load time. Production-grade pipelines use a three-layer approach:
- Data profiling before pipeline build—understand source data characteristics, null rates, format inconsistencies, and outliers before writing transformation logic
- Cleansing rules embedded in the transformation layer—handle known issues systematically, not case-by-case
- Post-load validation to confirm data arrived intact, complete, and within expected ranges
Skipping upfront profiling is one of the most common causes of costly pipeline rework. Teams that catch source data issues before deployment avoid the cascading fixes that follow a bad go-live.
Error Handling and Monitoring
Production pipelines fail. The question is whether they fail visibly or silently.
A reliable ETL service builds monitoring in from day one:
- Automated alerts when a pipeline job fails or produces anomalous outputs
- Detailed error logs that identify which records failed and why—not just that something went wrong
- Recovery checkpoints so a failure at 80% completion doesn't restart from zero
Retrofitting monitoring into an existing pipeline is harder than designing for it upfront—and considerably more expensive in engineering hours.
Scalability Planning
Pipelines built for today's data volumes break under tomorrow's production load. Scalability decisions made at design time include:
- Parallel processing for speed under heavy data volumes
- Incremental loading as the default strategy, reserving full loads for resets and initial population
- Cloud-native infrastructure that scales compute up or down based on workload—avoiding the over-provisioning that inflates costs when demand is low
Security and Compliance
Enterprise ETL pipelines touch sensitive data. Required controls include:
- Role-based access controls limiting who can view or modify pipeline logic and data
- Encryption in transit and at rest for all data movement
- Immutable audit logging to track data movement for compliance review
- Regulatory adherence relevant to the industry—HIPAA for healthcare data involving electronic protected health information, GDPR for pipelines handling EU personal data, CCPA for California consumer data
These requirements aren't optional in regulated industries. A pipeline that moves protected health information without proper HIPAA controls, for example, exposes the organization to audits, fines, and remediation costs that dwarf the original engineering investment.
Documentation and Version Control
When the engineer who built a pipeline leaves, undocumented transformation logic leaves the next team guessing. Debugging a production failure without context on why certain decisions were made adds hours—sometimes days—to resolution time.
Professional ETL services deliver:
- Pipeline architecture documentation
- Transformation logic records explaining why decisions were made, not just what the code does
- Version-controlled repositories where changes can be tracked, reviewed, and rolled back
Dynamic Data implements version control and automated testing in pipeline delivery—evidenced in their Zenus engagement, where dbt-managed pipelines included built-in testing to catch problems before they reached end users.

ETL vs. ELT: Which Approach Does Your Business Need?
The core difference: ETL transforms data before it reaches the warehouse; ELT loads raw data first and transforms it inside the warehouse using its own compute power.
Cloud-native warehouses like Snowflake and BigQuery have made ELT the dominant pattern in modern data stacks—they're purpose-built to handle transformation at scale without a separate processing layer.
The right choice depends on your compliance requirements, existing infrastructure, and how your analytics team works.
Choose ETL when:
- Operating in strict compliance environments (healthcare, banking) where data must be scrubbed before touching a central repository
- Integrating with legacy systems that lack scalable transformation capabilities
- Running highly complex transformations where pre-load preparation is more efficient than warehouse-side processing
Choose ELT when:
- Using modern cloud data warehouses that perform transformations at scale
- Analytics teams need raw, source-fidelity data available quickly for multiple downstream use cases
- Using tools like dbt, where transformation models are built and maintained inside the warehouse by analytics engineers

Dynamic Data's team works across both patterns, with dbt Certified Developers like Marcelo Bour leading ELT engagements on Snowflake, BigQuery, and Databricks. For Zenus, the team built a fully automated dbt transformation pipeline on Google Cloud that delivered real-time visibility into client data, cutting reporting lag from days to hours.
What to Look for in an ETL Pipeline Service Provider
Technical Credentials and Platform Depth
Look for certified data engineers with hands-on experience across the platforms in your existing stack. dbt Certified Developers, for example, demonstrate proficiency in transformation modeling, testing, documentation, and deployment—not just basic SQL.
Dynamic Data's team holds dbt Certified Developer credentials and has built pipelines across 35+ platforms and languages, spanning Snowflake, BigQuery, Databricks, AWS, and Azure. That breadth matters when integrating across a mixed technology environment without requiring a full stack overhaul.
End-to-End Ownership
The best ETL pipeline services don't hand over code and disappear. Look for providers who own the full lifecycle:
- Pipeline design and architecture
- Development, testing, and deployment
- Production monitoring and alerting
- Ongoing maintenance and iteration as business requirements change
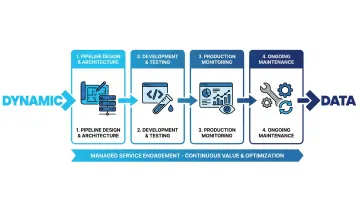
Without that ongoing ownership, your team inherits the maintenance burden—often without the context to handle it well.
Business Alignment Before Technical Execution
Great pipeline architecture starts with understanding what the pipeline needs to deliver. The code comes second.
Ask any provider: How do you gather requirements? How do you handle changing business needs mid-project? What does your documentation and handoff process look like?
The way Dynamic Data approached the Zenus engagement reflects this standard. Throughout the project, the team worked closely with Zenus's engineers to make architectural decisions collaboratively. The result was infrastructure shaped by the client's specific data goals—not retrofitted after the fact.
Frequently Asked Questions
What is an ETL pipeline?
An ETL pipeline is an automated workflow that Extracts data from source systems, Transforms it to meet quality and structural requirements, and Loads it into a destination like a data warehouse. The end result is raw data converted into something usable for analytics and business decisions.
What are the main stages of an ETL pipeline?
The three stages are Extract (pulling data from databases, APIs, files, and applications), Transform (cleaning, standardizing, and restructuring data to meet business requirements), and Load (delivering transformed data to a data warehouse or analytics platform for reporting and analysis).
Will AI replace ETL pipelines?
No—AI is enhancing pipelines, not replacing them. Tools can now automate anomaly detection, data quality flagging, and transformation suggestions. AI models themselves require clean, well-structured data delivered by reliable pipelines to function accurately, which makes the underlying infrastructure more critical, not less.
What is the difference between ETL and ELT?
ETL transforms data before loading it into the destination warehouse; ELT loads raw data first and transforms it inside the warehouse. ELT is now standard for cloud-native stacks; ETL is preferred when strict data governance or legacy system constraints require pre-load transformation.
How long does it take to build an ETL pipeline?
Timelines vary by complexity. Simple pipelines connecting a handful of sources can be built in days to a few weeks. Enterprise-grade pipelines with complex business logic and many integrations typically take several weeks to a few months.
What should I look for in an ETL pipeline service provider?
Prioritize certified technical expertise, familiarity with your existing data platforms, and end-to-end ownership from design through monitoring. The right provider understands your reporting and analytics goals before writing a single line of code.


