
The pattern behind most failures is consistent: vague use case definitions, underestimated data work, and models that never get properly validated before hitting production. Large enterprises with in-house data science teams run into these problems. Mid-sized businesses — typically relying on a combination of internal subject matter experts and external partners like Dynamic Data — run into them too.
This guide covers the full custom AI development process: what it actually involves, how to assess readiness before you start, the four implementation phases, and the most common failure points with practical fixes.
Key Takeaways
- Custom AI follows a defined sequence: use case discovery → data preparation → pilot testing → production scaling. Skipping phases causes failures.
- The most common mistake is starting model development before the business problem and data foundation are clearly defined.
- Only 7% of enterprises say their data is completely ready for AI. Treat data readiness as Phase 0, before any model work begins.
- Successful custom AI requires ongoing monitoring, drift detection, and retraining. It is never a one-time build.
- Companies that follow a structured roadmap achieve faster time-to-value and significantly lower abandonment rates.
What Custom AI Use Case Development Actually Involves
Custom vs. Off-the-Shelf AI
A custom AI use case is a targeted application of machine learning, NLP, computer vision, or predictive analytics built specifically to solve a defined business problem. That's meaningfully different from an off-the-shelf tool.
Off-the-shelf AI products deploy quickly and work reasonably well for generic tasks. The ceiling is low. They're trained on public or anonymized data — not your transaction patterns, your customer segments, your operational history. Custom AI is built on your proprietary data, tuned to your specific workflows, and improves over time as more of your data flows through it.
The tradeoff: it requires real investment to build, and that investment doesn't end at launch.
What the Process Covers
At a high level, custom AI development involves:
- Use case identification and prioritization — selecting the right problem to solve first
- Data preparation and infrastructure setup — the most underestimated phase
- Model development and pilot testing — building, training, and validating in a controlled environment
- Production scaling and operationalization — integrating into live systems with ongoing monitoring
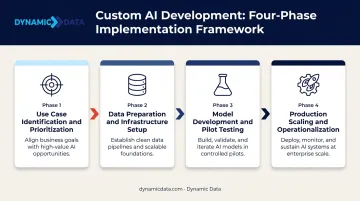
Shortcuts at any phase compound downstream. A poorly scoped use case produces a model nobody uses — and skipped data validation means production failures that testing never caught.
Realistic Expectations on Time and Resources
Small-to-mid-scale custom AI projects typically run 3–9 months from scoping to live deployment. They require collaboration between business stakeholders, data engineers, and model developers. And the work doesn't end at launch — models need monitoring, retraining, and periodic reassessment against business KPIs.
McKinsey's 2025 State of AI report puts the returns in concrete terms:
- 70% of strategy and finance teams reported revenue increases
- 66% of marketing and sales teams reported revenue increases
- 61% of supply chain teams reported cost reductions
That value concentrates in functions with clear decision workflows and strong data foundations — which is exactly where a well-scoped custom AI project should start.
Prerequisites: Is Your Business Ready to Build Custom AI?
Most companies underestimate what needs to be in place before development begins. These aren't optional prerequisites.
Data Readiness
The model is only as reliable as the data it trains on. Before any AI work starts, you need:
- Sufficient volume of historical or real-time data relevant to the outcome you're predicting
- Data that is clean, consistently structured, and properly labeled
- Accessible data — not locked in siloed spreadsheets, legacy systems, or inconsistent formats
A 2026 survey by Cloudera and HBR Analytic Services found only 7% of enterprises say their data is completely ready for AI, while 27% say it is not very or not at all ready. Most projects stall here, long before model development begins.
A modern data stack (cloud data warehouse, clean transformation pipelines, data governance policies) is a prerequisite before meaningful AI development can begin. In the Zenus engagement, for example, standing up a Google Cloud data warehouse with automated dbt pipelines was the necessary first step before any advanced analytics could be layered on top. Dynamic Data builds this foundation on platforms like Snowflake, BigQuery, and dbt as a standard part of pre-ML work.
Infrastructure and Integration Compatibility
The business must be able to access cloud or on-premise compute capable of supporting model training and deployment. Equally important: existing systems (CRM, ERP, reporting tools) need to receive and act on AI outputs. Assess API availability and data pipeline architecture before committing to a use case.
Organizational Readiness
Successful custom AI projects require:
- Executive buy-in with budget commitment for the full lifecycle, not just the build phase
- A clearly defined business owner for the use case
- At least one internal champion who can bridge business and technical teams
- A defined success metric — the model needs a measurable target to optimize for
When Not to Proceed
Custom AI development should not begin if any of these conditions exist:
- Insufficient or non-representative training data
- No defined success metric for the model output
- No plan for how model predictions will be acted upon by the business
- No budget or timeline for ongoing maintenance post-deployment
None of these gaps can be patched mid-project. Resolve them before scoping begins, or the engagement will stall at the worst possible moment.
How to Develop and Implement a Custom AI Use Case (Step-by-Step)
Building a custom AI use case follows a structured sequence of phases, each one creating the foundation the next depends on. Compressing or skipping steps (particularly data preparation and pilot validation) is the leading cause of failed AI projects.
Phase 1: Use Case Discovery and Prioritization
Identify the right problem to solve first by mapping high-friction, data-rich business processes — such as manual forecasting, repetitive document classification, or demand planning. Not every pain point is worth automating; the goal here is finding problems where AI creates measurable ROI and where you already have (or can acquire) the data to train a model.
A useful prioritization framework weighs three factors:
- Impact: How much time, cost, or error does solving this problem eliminate?
- Data readiness: Is there sufficient historical data available to train and validate a model?
- Feasibility: Can the solution be built within your current infrastructure and team capabilities?
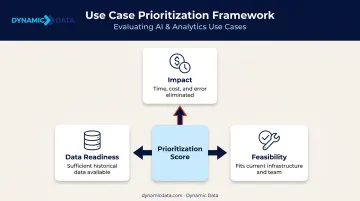
Score each candidate use case against these factors. The highest-scoring combination of impact and feasibility — not just the most ambitious idea — should go first.


