
The systems most organizations still rely on — static rules, fixed thresholds, manual logic — were built for a different threat environment. Machine learning hasn't just become a competitive advantage in fraud detection; for any organization processing transactions at scale, it's become the baseline requirement.
This guide covers how ML detects fraud, which algorithms perform best, real-world applications, the challenges teams face in production, and the data infrastructure required to make it all work.
Key Takeaways
- Rules-based fraud systems can't adapt to new tactics and generate false positive rates that overwhelm teams — up to 95% of AML alerts are false positives
- ML models learn from historical patterns and assign real-time risk scores, catching fraud that static rules miss
- Gradient boosting (XGBoost, LightGBM) is the production standard for tabular fraud data; graph neural networks excel at detecting fraud rings
- Class imbalance, model drift, and data quality are the top challenges that derail ML fraud programs
- Model choice matters less than data infrastructure — both must be built together
Why Traditional Fraud Detection Falls Short
Rules-based fraud detection works by evaluating transactions against a predefined set of conditions: if a transaction exceeds a dollar threshold, originates from a flagged country, or occurs outside normal hours, flag it. Simple in concept, but structurally brittle at scale.
Three structural weaknesses make rules-based systems inadequate at scale:
- Stay static until manually updated — fraudsters change tactics; the ruleset doesn't
- Generate enormous noise: up to 95% of AML transaction monitoring alerts are false positives, burying analysts and blocking legitimate customers
- Damage revenue directly — false declines in e-commerce cost merchants roughly 6% of revenue, and blocked customers rarely try again
Modern fraud has exploited these gaps directly. Synthetic identity fraud — combining real and fabricated data to create fictitious personas — reached an all-time high in financial services in 2024. Account takeover fraud hit $15.6 billion in losses that same year, affecting 5.1 million consumers.
Coordinated fraud rings, where dozens of accounts act in concert, are structurally invisible to per-transaction rule evaluation.
Chargebacks compound the problem. Cardholders have up to 120 days to file a dispute, meaning fraud that slipped through might not surface for weeks — long after the window for pattern correction.
That said, ML doesn't eliminate rules entirely. The strongest fraud strategies combine rule-based guardrails — fast, deterministic checks for known bad patterns — with adaptive ML models that handle everything rules can't anticipate.
How Machine Learning Detects Fraud: Core Mechanisms
Supervised Learning: Teaching Models to Recognize Fraud
Supervised learning is the foundation of most production fraud systems. Models train on labeled historical data — transactions tagged as fraud or legitimate — and learn which combinations of features predict each outcome.
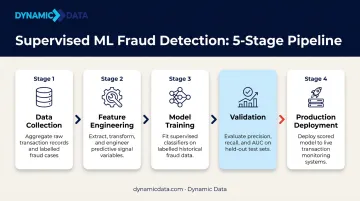
The pipeline follows a consistent structure:
- Data collection — assemble historical transactions with confirmed fraud labels
- Feature engineering — transform raw data into signals the model can use
- Model training — fit the model on labeled examples
- Validation — test against held-out data the model hasn't seen
- Production deployment — score new transactions in real time
At the moment of a transaction, the model outputs a probability score (typically 0–100). Businesses configure thresholds: scores below a cutoff are approved automatically, scores in a middle band go to manual review, and high-risk scores trigger an automatic block. Stripe Radar uses this approach, drawing on transaction data across its entire merchant network to continuously refine its scoring thresholds.
Unsupervised Learning: Catching What Labels Miss
Not all fraud arrives with a label. Novel attack patterns can't be pre-categorized as fraud because there are no historical examples to train on.
Unsupervised anomaly detection solves this by learning what "normal" looks like and flagging deviations. There's no target variable; the model identifies statistical outliers from baseline behavior. eBay's FinDeepBehaviorCluster uses this approach for behavioral anomaly detection without requiring labeled training data. Visa also relies on unsupervised techniques to detect previously unseen fraud patterns before they become labeled events.
Feature Engineering: What the Model Actually Learns From
Both supervised and unsupervised models depend on the same foundation: engineered features, not raw transaction data. The winning solution in the IEEE-CIS Kaggle fraud detection competition used 262 engineered features, including transaction amount decomposition, velocity aggregations, and device-card combinations.
Production fraud features generally fall into four categories:
- Identity signals: email domain patterns, device fingerprints, account age, phone number validation
- Transaction signals: amount, merchant category, velocity (how many transactions in the past hour), location
- Behavioral signals: session duration, copy-paste behavior, mouse movement patterns, browsing depth
- Network signals: shared devices, IP addresses, or payment methods across multiple accounts
Feature quality often determines outcome more than algorithm choice. In the IEEE-CIS competition, top-ranked teams used similar gradient boosting architectures — what separated them was the depth and creativity of their feature sets.
Key ML Algorithms Used in Fraud Detection
Logistic Regression and Decision Trees
Logistic regression is the baseline model for most fraud teams. It's fast, interpretable, and quantifies exactly how much each feature shifts the fraud probability — useful when regulators or auditors need to understand why a transaction was blocked. On the IEEE-CIS benchmark, logistic regression achieved 61% accuracy, which illustrates both its limitations and why it's used as a baseline rather than a final solution.
Random Forest extends decision trees through bagging: combining many trees reduces variance, handles imbalanced datasets better than single models, and retains interpretability through feature importance scores. A single decision tree hit 87% on the same benchmark — better than logistic regression, but still well below what ensemble methods achieve.
Gradient Boosting: XGBoost and LightGBM
Gradient boosting is the current standard for tabular fraud data. Rather than training models independently, it builds them sequentially, with each new model correcting the errors of the previous one.
An XGBoost, LightGBM, and CatBoost ensemble achieved a private AUC of 0.9459 on the IEEE-CIS Kaggle fraud detection benchmark, outperforming simpler methods by a wide margin. A stacking ensemble of the same three algorithms later achieved AUC-ROC of 0.99 on the same dataset.
Key advantages for fraud teams:
- Handles class imbalance through built-in class weight adjustments
- More interpretable than neural networks (SHAP values work well with these models)
- Faster to train and iterate than deep learning approaches
- Consistently tops production fraud system benchmarks
Neural Networks and Deep Learning
Deep learning is the right choice in specific scenarios — not the default. RNNs and LSTMs excel at modeling transaction sequences where temporal order matters. Feedzai's interleaved sequence RNNs outperformed tree-based models for card fraud by treating payments as a sub-sequence of card history, eliminating the need for manual velocity feature engineering.
That performance advantage comes with a cost. Neural networks function as black boxes, which complicates audit and compliance use cases where regulators require explanations of individual decisions.
When to consider deep learning:
- Transaction sequence modeling where order and timing carry signal
- High-volume card fraud where velocity features are too expensive to engineer manually
- Scenarios where raw accuracy outweighs the need for model explainability
Graph-Based Methods and Anomaly Detection
Individual transaction models have a blind spot: they evaluate each event in isolation and miss coordinated multi-account fraud. Graph neural networks (GNNs) address this directly by modeling accounts, devices, and IP addresses as nodes with edges representing connections between them.
KumoRFM, a GNN-based approach, achieved 89% accuracy on the SAP SALT enterprise benchmark versus 75% for PhD-level data scientists using expert-tuned XGBoost. GNNs can also detect fraud rings 6–7 hops deep in transaction graphs, a depth that flat-table models structurally cannot reach.

For teams without labeled fraud data, Isolation Forest provides an effective unsupervised option: it flags rare anomalies by isolating outliers in the feature space without requiring any fraud labels to train on.
Real-World Use Cases
Payment fraud detection remains the most widespread ML application in financial services. Card-not-present (CNP) fraud accounts for roughly 80% of all e-commerce credit card fraud losses. ML models evaluate each transaction in milliseconds — scoring against transaction amount, merchant category, device fingerprint, and location — before a charge clears. Payment systems allocate just 10–50ms for model inference within a 100ms total authorization window, which makes infrastructure as important as model accuracy.
Account takeover (ATO) prevention is growing just as fast. ATO attempts against consumers increased by 250% in 2024, and the damage extends beyond the attack itself — 42% of victims closed the affected account afterward. ML detects anomalous login behavior (new device, unfamiliar location, rapid credential attempts) and triggers step-up authentication or blocks access before harm occurs.
These core use cases are expanding across industries. ML fraud detection now addresses:
- Fabricated borrower identities holding approximately $1.8 billion in auto loan credit (synthetic identity fraud)
- Synthetic voice attacks against insurers, up 475% in 2024, driving a 19% overall rise in insurance fraud
- Automated account creation and point manipulation in loyalty programs, caught through behavioral anomaly detection
- Irregular payment amounts, vendor patterns, and approval workflows in B2B invoice fraud
Challenges in ML Fraud Detection (and How to Solve Them)
Class Imbalance
In production systems, fraud represents less than 0.2% to roughly 1% of all transactions. A model that predicts "legitimate" for every transaction would still achieve 99% accuracy, which makes raw accuracy a meaningless metric for fraud detection.
Solutions that work:
- SMOTE: Generates synthetic fraud examples to balance training data. In a 2025 study, SMOTE improved an LSTM-XGBoost model's F1-score from 0.82 to 0.91
- Class weight adjustments: Gradient boosting models support direct minority-class weighting during training
- AUPRC over accuracy: Switch from accuracy to Precision, Recall, F1, and AUPRC (Area Under the Precision-Recall Curve) — the most reliable metric for imbalanced datasets because it measures precision as recall scales up
Model Interpretability
Solving imbalance gets you a working model. The next problem: regulators and fraud analysts need to understand why a transaction was blocked, and complex models don't explain themselves by default.
SHAP values solve this by attributing each prediction to specific input features, showing exactly how much "transaction velocity" or "device age" contributed to a given risk score. Financial institutions integrate SHAP and LIME frameworks into risk scoring systems specifically to meet regulatory audit requirements.
On the IEEE-CIS dataset, SHAP analysis identified the top 30 most influential features, enabling transparent compliance documentation alongside high model accuracy.
Data Quality and Label Reliability
Even a well-interpreted model fails if it's trained on unreliable labels. Cardholders have up to 120 days to file a chargeback, meaning recent transaction data often contains fraud mislabeled as legitimate. The chargeback simply hasn't arrived yet, and training on that data teaches the model the wrong lesson.
Addressing this requires:
- Structured label hierarchies that capture fraud type and severity
- Continuous feedback loops that update labels as investigations close
- Holding out recent data from training until labels stabilize
Model Drift and Ongoing Maintenance
Label quality protects the model at training time. Drift is what degrades it afterward. Fraud tactics evolve, and the patterns a model learned six months ago may not reflect today's attacks — performance erodes silently unless monitored. Credit card fraud models are retrained weekly in production environments; some require daily cycles during high-fraud periods.
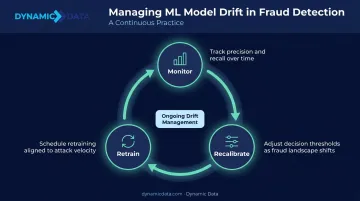
Managing drift requires three ongoing practices:
- Track precision and recall over time, not just at deployment
- Schedule retraining cycles aligned to attack pattern velocity
- Recalibrate decision thresholds as the fraud landscape shifts
Building the Data Foundation That Makes ML Fraud Detection Work
A well-trained model means little without infrastructure that can feed it clean, consistent, real-time data. In fraud detection, the data stack is just as consequential as the model itself.
A fraud-ready data stack requires:
- Reliable data collection across transaction systems, identity providers, and behavioral event streams
- Preprocessing pipelines that normalize and validate data before it reaches the model
- Feature stores that serve consistent features for both model training and real-time inference — eliminating training-serving skew
- Low-latency model serving capable of returning predictions within 10–50ms
Pulling from multiple sources — internal transaction logs, third-party identity signals, behavioral streams — and unifying them in real time is where most fraud systems struggle. Data orchestration is frequently the harder problem, and it's where purpose-built pipelines on platforms like Snowflake, Databricks, BigQuery, and dbt make a measurable difference.

Compliance and Data Governance
Data privacy and regulatory compliance can't be an afterthought. Fraud detection systems process sensitive PII, and automated decisioning falls within the scope of GDPR Article 22 when transactions are declined based solely on model output. Key considerations include:
- Data minimization — collect only what the model needs
- Role-based access controls on fraud data
- Audit trails documenting model decisions
- Alignment with GDPR, CCPA, and any sector-specific regulations
Skipping governance doesn't just create legal exposure — it also erodes the audit trails needed to investigate disputes, refine models, and satisfy regulators when decisions are challenged.
Frequently Asked Questions
How is machine learning used for fraud detection?
ML systems analyze historical transaction and behavioral data to learn which patterns distinguish fraud from legitimate activity. At the moment of a new transaction, the model applies those learned patterns to assign a risk score, automatically approving, flagging, or blocking based on configured thresholds.
Which machine learning algorithms are used for fraud detection?
The most common are logistic regression, random forest, gradient boosting (XGBoost, LightGBM, CatBoost), neural networks (RNNs/LSTMs for sequences), and Isolation Forest for unsupervised anomaly detection. Gradient boosting dominates production tabular fraud systems; graph neural networks are emerging for fraud ring detection.
Is fraud detection a classification problem?
In supervised learning contexts, yes — typically binary classification (fraud vs. not fraud). It can also be framed as anomaly detection (unsupervised, no labels required) or as a regression problem outputting a continuous risk score — the right framing depends on whether labeled historical fraud data exists.
What impact can machine learning have on financial fraud detection?
ML enables real-time detection at scale, cuts false positives vs. rules-only systems, and adapts to new tactics through retraining. Mastercard's AI doubled fraud detection speed and improved detection rates by up to 20%, while Visa's AI systems prevented $40 billion in fraudulent activity in 2024 alone.
What is an example of fraud detection?
A cardholder's transaction at an unfamiliar merchant triggers ML scoring: the model compares the transaction against the cardholder's historical purchase patterns, device data, and timing. A high risk score triggers a step-up authentication challenge before the charge is approved — stopping the fraud without blocking legitimate purchases.


