
Introduction
Your CRM lives in Salesforce. Your marketing data is in HubSpot. Financial records sit in an ERP. Product usage data streams from a custom database. And someone, somewhere, is still maintaining a spreadsheet that nobody fully trusts.
This is the reality for most mid-market and enterprise teams today — data scattered across dozens of systems, none of it speaking the same language. The average company manages 305 SaaS applications, and without a coherent integration layer, even well-staffed data teams spend more time reconciling numbers than acting on them.
Choosing the wrong integration tool compounds the problem. A poor fit can cost months of engineering rework, create unexpected cost spikes as data volumes grow, and erode confidence in the entire data stack.
What follows is a practical breakdown of five widely used tools — Fivetran, Airbyte, dbt, Matillion, and Informatica — covering where each fits, where each falls short, and how to evaluate them against your actual requirements.
Key Takeaways
- Data integration tools automate moving, transforming, and consolidating data from multiple sources into a single destination for analysis.
- Leading tools fall into distinct categories — managed ELT, open-source ELT, transformation, visual ETL, and enterprise platforms — each built for different use cases.
- The right choice depends on your team's technical skills, data sources, and whether you need real-time or batch processing.
- Pricing models vary widely, and costs frequently escalate faster than teams anticipate.
- No single tool fits every business; most modern stacks combine two or more tools.
What Is Data Integration and Why Does It Matter?
Data integration is the process of pulling data from multiple sources — SaaS apps, databases, spreadsheets, APIs — transforming it into a consistent format, and delivering it to a destination (typically a cloud data warehouse) where it can be analyzed and acted on.
ETL vs. ELT: What Changed
Two dominant approaches define how this happens:
- ETL (Extract, Transform, Load): Data is cleaned and structured before it reaches the warehouse. Traditional approach, still relevant for compliance-heavy environments.
- ELT (Extract, Load, Transform): Raw data lands in the warehouse first; transformations happen inside using the warehouse's own compute. Preferred by cloud-first teams.
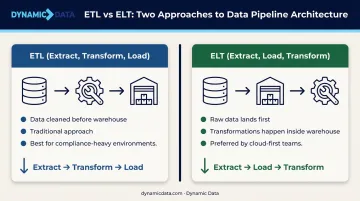
Modern cloud warehouses like BigQuery, Snowflake, and Redshift have made ELT the practical default — their elastic compute handles in-warehouse transformation more efficiently and cheaply than external engines ever could.
Why Getting This Wrong Is Expensive
Poor data integration isn't just a technical inconvenience. Over 25% of organizations lose more than $5 million annually due to poor data quality, and 42% of enterprises have experienced delayed or failed AI projects specifically because of data readiness issues.
The downstream consequences are consistent across industries:
- Reports get built on mismatched numbers
- AI and ML initiatives stall at the data preparation stage
- Engineering teams burn capacity maintaining broken pipelines instead of building
Choosing the right integration tool is the first decision that determines whether you avoid these problems — or inherit them.
Top Data Integration Tools to Know
These tools were selected based on connector breadth, cloud-warehouse compatibility, team accessibility, reliability, and value at scale.
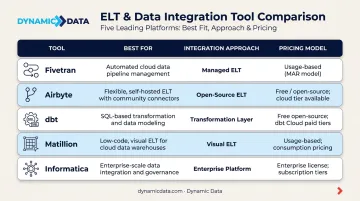
Fivetran
Fivetran is a fully managed, cloud-native ELT platform that automates data ingestion from 700+ sources into warehouses like BigQuery, Snowflake, and Redshift — with virtually zero pipeline maintenance once connectors are live.
Fivetran's automated schema drift handling stands out: when a source system changes its structure, Fivetran adapts without manual remapping. It also supports log-based CDC (Change Data Capture) for near-real-time updates and includes enterprise-grade security across all tiers.
The tradeoff is cost predictability. Pricing is based on Monthly Active Rows (MAR), which can escalate significantly as data volumes grow. Teams should model costs at 6–12 months of projected scale before committing — not just what it costs on day one.
| Dimension | Details |
|---|---|
| Integration Approach | Fully managed ELT; warehouse-first ingestion |
| Best For | Teams wanting automated, low-maintenance pipelines |
| Pricing Model | Usage-based (Monthly Active Rows); free tier available |
Airbyte
Airbyte is an open-source ELT platform with 600+ connectors and the option to self-host for full infrastructure control, or use Airbyte Cloud for a managed experience. With over 21,300 GitHub stars, it's the most widely adopted open-source option in this category.
Extensibility is where Airbyte earns its following. Teams can build custom connectors via a Python-based Connector Development Kit, and CDC is powered by Debezium — a mature engine that experienced engineers can debug and tune directly.
The honest trade-off: self-hosted Airbyte has $0 software cost, but infrastructure typically runs $500 to $3,000+/month depending on scale, and your team absorbs all upgrade, monitoring, and maintenance responsibility. It's best suited for engineering-led teams who want ownership of their pipeline layer, not a managed black box.
| Dimension | Details |
|---|---|
| Integration Approach | Open-source ELT; self-hosted or cloud-managed |
| Best For | Engineering teams wanting connector flexibility and full control |
| Pricing Model | Free (self-hosted); consumption-based for Airbyte Cloud |
dbt (data build tool)
dbt is not an ingestion tool. It's the transformation layer — the industry standard for writing SQL-based models, testing data quality, and documenting pipelines using software engineering best practices, all inside your cloud data warehouse.
dbt works alongside ingestion tools like Fivetran or Airbyte: once raw data lands in the warehouse, dbt cleans, models, and structures it for reporting and analysis. That separation of concerns is what makes modern ELT stacks so maintainable.
The scale of adoption reflects that position: 5,000+ organizations rely on dbt Cloud, and dbt Labs surpassed $100 million in ARR — scaling from $2M to $100M in just four years. Customers include Nasdaq, Siemens, HubSpot, and Conde Nast.
Dynamic Data's certified dbt Developers implement and optimize dbt workflows across client data stacks. A recent project with Zenus — a fully automated transformation and testing pipeline on Google Cloud — delivered real-time data visibility, automated quality checks, and a pipeline architecture that scales with product growth.
| Dimension | Details |
|---|---|
| Integration Approach | Transformation only (ELT's "T"); SQL-based, warehouse-native |
| Best For | Teams needing reliable, tested, version-controlled data models |
| Pricing Model | dbt Core is free; dbt Cloud starts at ~$100/developer/month |
Matillion
Matillion is a cloud ELT platform offering a visual, low-code job builder for teams that want SQL-driven transformation logic without writing orchestration code from scratch. It runs on Snowflake, BigQuery, Redshift, and Databricks.
Its pushdown execution model handles transformations directly inside the warehouse — no separate compute layer. For teams managing multi-terabyte datasets with complex transformation requirements, this matters. The 2025 addition of Maia, Matillion's agentic AI assistant, adds natural-language pipeline development for teams with mixed technical skill levels.
One cost consideration worth pressure-testing before signing an annual contract: pricing is credit-based (tied to compute usage), but warehouse compute costs are incurred separately from platform licensing. Matillion users consistently flag this dual exposure in reviews, so model both cost lines before committing.
| Dimension | Details |
|---|---|
| Integration Approach | Cloud ELT with visual transformation builder; warehouse-native |
| Best For | SQL-heavy data engineering teams managing complex warehouse transformations |
| Pricing Model | Usage-based (Matillion Credits); enterprise tiers require annual contracts |
Informatica
Informatica's Intelligent Data Management Cloud (IDMC) is an enterprise-grade platform covering the full data lifecycle: ETL/ELT, data quality, governance, master data management, and application integration — consolidated under a single vendor.
The CLAIRE AI engine automates data discovery, schema mapping, and data cleansing — directly relevant for organizations preparing data for AI and ML workloads at scale. Informatica has been named a Gartner Magic Quadrant Leader for Data Integration Tools for the 20th consecutive year, and the platform handles over 22 trillion cloud transactions per month.
That said, Informatica is not for everyone. Implementation is complex, pricing is undisclosed (custom quotes only), and the platform assumes formal governance processes rather than agile, iterative pipelines. It's purpose-built for large enterprises with compliance requirements and dedicated data governance teams.
| Dimension | Details |
|---|---|
| Integration Approach | Enterprise ETL/ELT + governance, data quality, and MDM |
| Best For | Large enterprises needing compliance, data lineage, and AI-ready data |
| Pricing Model | Consumption-based (Informatica Processing Units); custom quotes required |
How to Choose the Right Data Integration Tool
Start With Sources and Destinations
Map where your data currently lives and where it needs to go. Then verify that any tool under consideration has native, production-maintained connectors for your specific sources — not beta or community-maintained ones that will require ongoing engineering attention to keep running.
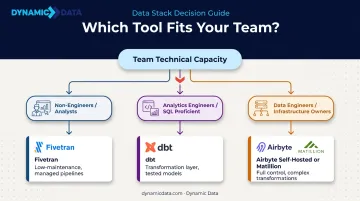
Be Honest About Your Team's Technical Capacity
This is where most evaluations go wrong. Ask not just who will set pipelines up during a demo, but who will own them six months from now.
- Airbyte (self-hosted) and Matillion assume data engineering skills and ongoing infrastructure ownership
- Fivetran suits teams with analysts, RevOps, or non-engineers maintaining pipelines day-to-day
- dbt requires SQL proficiency and ideally an analytics engineer — but the payoff is long-term pipeline stability and reduced debugging time
Clarify Real-Time vs. Batch Needs
Most business reporting workflows run fine on hourly or daily batch loads. Real-time CDC adds complexity and cost — only invest in it when your use case genuinely requires sub-minute freshness (operational dashboards, fraud detection, ML feature pipelines).
72% of global organizations have adopted event-driven architecture, but only 13% have reached mature, organization-wide implementation. If your team isn't in that mature 13%, batch or micro-batch is likely the right starting point — real-time adds infrastructure overhead that few organizations are ready to absorb.
Pressure-Test Pricing at Scale
Request or calculate your bill at 6 and 12 months of projected data volume growth. Row-based and credit-based models can increase dramatically when:
- Data volumes grow
- New fields or sources are added
- Sync frequency increases
Fixed or workload-based pricing is generally easier for finance teams to forecast and approve.
Consider Working With an Experienced Partner
For businesses building or modernizing their data stack, tool selection is an architectural decision with long-term consequences. Dynamic Data works across 35+ platforms and includes certified dbt Developers who help clients select, implement, and optimize the right combination of integration tools for their specific architecture and goals. Getting the tool selection right from the start avoids costly rework and architectural debt down the line.

Conclusion
The data integration tool landscape is mature but fragmented. The right choice is not the most popular tool or the one with the longest feature list — it's the one that fits your team's skills, your existing stack, your data destinations, and your growth trajectory without creating unsustainable cost or maintenance overhead.
Tool selection is an architectural decision. Evaluate how each option fits into your broader pipeline — from ingestion through transformation to reporting — whether it scales predictably, and whether your team can maintain it independently.
When that evaluation surfaces more complexity than your team can absorb internally, that's where a specialized partner adds real value. Dynamic Data works with mid-market and enterprise teams on tool selection, ETL/ELT pipeline implementation, and ongoing data engineering — drawing on expertise across Snowflake, BigQuery, dbt, and 35+ other platforms to build stacks that teams can actually own and scale.
Frequently Asked Questions
What is the best data integration platform?
The right platform depends on your team's technical capacity, data sources, and warehouse destination. Fivetran suits teams wanting low-maintenance managed ingestion; Airbyte suits engineering teams wanting full pipeline control and customization.
What are the top ETL tools?
Leading options include Fivetran and Airbyte for ingestion, dbt for transformation, Matillion for combined ELT with visual development, and Informatica for enterprise-grade lifecycle management. Most modern stacks pair a dedicated ingestion tool with a separate transformation layer rather than a single all-in-one product.
What are the best AI-powered data integration tools in 2025?
Informatica's CLAIRE engine leads in enterprise AI — automating schema mapping, data discovery, and pipeline suggestions. Matillion's Maia assistant adds natural-language pipeline development, and Fivetran's platform increasingly focuses on AI data readiness as a core capability.
What is the best data integration tool to move data to BigQuery?
Fivetran and Airbyte are the most commonly used tools for loading data from sources like SQL Server or Amazon S3 into BigQuery. Both offer native BigQuery connectors, with dbt handling downstream transformations once data is in the warehouse.
Which data integration tool is best for data migration?
Data migration differs from ongoing integration — Fivetran, Airbyte, and Informatica all support bulk historical loads, but migration projects require additional data quality validation and careful schema mapping before going live.
Which cloud data warehouse is best?
Snowflake, Google BigQuery, and Amazon Redshift are the three dominant options. BigQuery suits Google Cloud-centric stacks and pay-per-query workloads; Snowflake offers strong multi-cloud flexibility; Redshift integrates tightly with AWS services. Your existing cloud infrastructure is typically the deciding factor.


