
Introduction
Most large enterprises now run workloads across three or more cloud environments — yet the data those environments produce rarely speaks to each other. ML engineers wait weeks for clean training sets. Analysts debate which dashboard is actually correct. Multi-cloud flexibility, in practice, becomes a data fragmentation problem.
According to the Flexera 2024 State of the Cloud Report, 89% of organizations now employ multi-cloud strategies — yet managing cloud complexity remains the top challenge for the second consecutive year. That gap between adoption and control is where integration strategy lives.
This guide gives you a practical path from fragmented to unified. It covers:
- What enterprise data integration means in a multi-cloud context
- Why the absence of a unified strategy is expensive
- The five core integration patterns and when to use each
- A framework for building your integration roadmap
- The governance principles that make integrated data trustworthy
Key Takeaways
- Multi-cloud is the enterprise default; without a deliberate integration strategy, fragmented data creates more friction than value.
- Enterprise data integration connects all business systems into governed, reliable pipelines — multi-cloud integration extends that across two or more cloud providers.
- Five core patterns (ETL/ELT, API-based, event-driven, data virtualization, and CDC) serve different use cases and are often combined.
- Common challenges include data residency constraints, API mismatches, egress costs, schema conflicts, and limited cross-cloud observability.
- Governance, security, and data quality must be built into the integration layer from day one.
What Is Enterprise Data Integration in a Multi-Cloud Context?
Enterprise data integration is the practice of connecting all core business systems — CRMs, data warehouses, analytics platforms, ERP systems, and cloud applications — so data moves reliably across the organization. What separates it from ad hoc point-to-point connections is the emphasis on standardized pipelines, shared data models, and governed flows that any team can trust.
Multi-cloud integration is a specific discipline within that broader practice: coordinating those data flows across two or more public cloud providers (AWS, Azure, Google Cloud) alongside any on-premises systems. It introduces challenges that standard integration approaches weren't designed to handle — provider-specific APIs, regional data storage rules, and native tooling that doesn't translate across platforms.
ETL Is a Technique, Not a Strategy
ETL (Extract, Transform, Load) is one integration pattern — not a synonym for enterprise data integration. A mature multi-cloud strategy deploys multiple methods simultaneously, selected based on:
- Latency requirements: real-time streaming vs. scheduled batch processing
- Data volume: micro-batch streaming vs. large historical loads
- Governance constraints: whether data can move across regions or must remain in place
- System type: operational databases, cloud warehouses, or SaaS platforms each require different approaches
Choosing the right pattern for each scenario is where integration strategy begins — and where most multi-cloud implementations either hold together or break down.
Why Multi-Cloud Environments Need a Unified Integration Strategy
The Shadow Integration Problem
When there's no central integration strategy, individual teams solve their own data access problems. Consider what that looks like in practice: a marketing analyst writes a Python script against the AWS data lake, an engineering team hard-wires Azure to their reporting database, and a finance team exports CSVs by hand from a SaaS platform every Monday morning.
Over time, these ad hoc connections accumulate into undocumented, brittle pipelines. Each new cloud service added means more failure points, more maintenance overhead, and more ownership gaps. The MuleSoft 2025 Connectivity Benchmark Report found that 95% of organizations report facing integration challenges, with outdated architectures identified as the primary obstacle to AI implementation.
Fragmented Data Means Fragmented Truth
Cloud-native services produce data in incompatible schemas, use different naming conventions for identical metrics, and store records in conflicting formats. Without integration, cross-cloud reporting becomes unreliable — different teams operate from different versions of the same facts. Poor data quality costs organizations an average of $12.9 million per year, according to Gartner, and 59% don't even measure it.
AI and ML Hit a Data Wall
That data quality gap doesn't stay in the reporting layer — it flows directly into AI initiatives. Gartner projects that through 2026, companies will abandon 60% of AI projects that aren't supported by AI-ready data. Separately, at least half of generative AI projects were abandoned after proof of concept in 2024 — poor data quality and fragmented pipelines cited as primary causes.
Training data scattered across cloud environments, inconsistently formatted, and impossible to keep current will undermine even well-designed models. The algorithm rarely is the problem — the integration layer is.

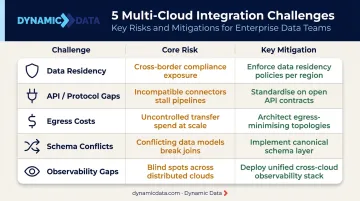
Core Challenges of Multi-Cloud Data Integration
Understanding where multi-cloud integration breaks down is half the battle. These five challenges appear consistently across enterprise environments.
Data Residency and Sovereignty
GDPR Articles 44–49 govern all cross-border transfers of personal data. HIPAA imposes encryption requirements and penalties ranging from $137 to over $2 million per violation. When data lives across clouds hosted in different regions, residency rules must be built into integration pipelines from the start — retrofitting compliance onto an existing architecture rarely works.
API and Protocol Inconsistency
Cloud-native services, legacy on-premises systems, and SaaS applications communicate through different protocols: REST, SOAP, GraphQL, batch file transfers, and proprietary APIs. Bridging these across cloud environments requires deliberate protocol translation. Connector availability gets you partway there; handling format conversion, authentication differences, and error behavior across each boundary is where the real work lives.
Cross-Cloud Egress Costs
Moving data between cloud providers has a price. AWS inter-region data transfer runs $0.09 per GB in both directions. At scale, poorly designed integration architecture that triggers unnecessary data movement creates real budget exposure — separate from the latency it introduces in real-time pipelines.
Schema and Identity Conflicts
The same customer might exist in AWS with a UUID, in Azure with an email as the primary key, and in a SaaS CRM with a sequential integer ID. Without entity resolution and master data management, merging these records produces duplicates, misattributions, and analytics outputs no one can trust.
Observability Gaps Across Cloud Boundaries
Each major provider has native monitoring tools that don't communicate with each other. When a pipeline spans AWS, Azure, and GCP, failures in one segment can propagate silently until downstream reports are already corrupted. A unified observability layer — one that aggregates logs, metrics, and alerts across all three providers — is what makes cross-cloud pipelines actually debuggable when something goes wrong.
| Challenge | Core Risk | Key Mitigation |
|---|---|---|
| Data Residency | Regulatory penalties | Build residency rules into pipeline design |
| API/Protocol Gaps | Integration failures | Protocol translation layer, not just connectors |
| Egress Costs | Budget overruns | Minimize unnecessary cross-cloud data movement |
| Schema Conflicts | Duplicate/corrupt records | Entity resolution and master data management |
| Observability Gaps | Silent pipeline failures | Unified monitoring across all cloud providers |
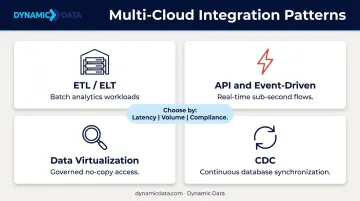
Integration Patterns and Approaches for Multi-Cloud Environments
No single pattern handles all multi-cloud data flows. Mature organizations typically combine two or three patterns based on latency needs, data volume, and governance requirements — the four approaches below cover the most common configurations.
ETL and ELT for Batch Analytics Workloads
ETL transforms data before loading it into a target system. ELT loads raw data first and uses the compute power of modern cloud warehouses — Snowflake, BigQuery, Redshift — to transform it after ingestion.
ELT has become the dominant approach for cloud-native analytics. Three factors drive its adoption:
- Raw data is preserved for reprocessing if requirements change
- Transformations can evolve without re-extraction
- Cloud warehouses handle the compute efficiently at scale
That said, TDWI research found 73% of organizations still rely on traditional ETL processes — adoption of ELT is growing but the transition is uneven.
Best for: Consolidating historical performance data from multiple cloud sources into a central warehouse for reporting, attribution modeling, or business intelligence.
API-Based and Event-Driven Integration for Real-Time Flows
API-based integration enables on-demand, bidirectional data exchange using RESTful or GraphQL APIs — well-suited for synchronizing operational data between cloud-hosted CRMs, marketing platforms, and customer databases.
Event-driven architectures (Apache Kafka, cloud-native event buses) trigger workflows based on system events in real time. Over 40% of the Fortune 500 rely on Confluent's Kafka platform, and 86% of IT leaders are prioritizing data streaming investments in 2024.
Best for: Fraud detection, inventory updates, real-time personalization — any use case requiring sub-second data flows across cloud environments.
Data Virtualization for Governed, No-Copy Access
Data virtualization creates a logical abstraction layer that queries data directly in its source system, presenting a unified view without physically moving or replicating it.
Key advantages:
- Eliminates data duplication and reduces egress costs
- Works well where data movement is restricted by regulation or security policy
- No pipeline to maintain for the virtualization layer itself
Trade-off: Query latency is higher than physical integration, making it unsuitable for high-frequency operational workloads.
Change Data Capture (CDC) for Continuous Synchronization
CDC identifies and streams only the records that have changed in a source system since the last extraction — monitoring database transaction logs rather than scanning full tables. This reduces compute overhead substantially compared to bulk reloads, capturing inserts, updates, and deletes in exact order with minimal impact on source database performance.
Best for: Keeping CRM, ERP, and cloud databases continuously in sync across environments without repeated bulk transfers — particularly valuable when minimizing data movement is both a cost and compliance priority.
How to Build a Multi-Cloud Data Integration Strategy
Start with Business Outcomes, Not Technology
Before selecting platforms or patterns, define the decisions that unified data needs to enable. Which cross-cloud reports are currently unreliable? Which AI use cases are blocked by data preparation? Which operational processes should be automated?
Working backwards from outcomes prevents over-engineering and ensures integration investments map to measurable business value — not technical completeness for its own sake.
Design for Cloud-Agnosticism Using Open Standards
Use standardized APIs, open data formats, and transformation logic that isn't locked to a single provider's ecosystem. Tools like dbt enable cloud-portable transformation workflows that run consistently across Snowflake, BigQuery, and Redshift — reducing lock-in risk as cloud footprints change.
Dynamic Data's certified dbt developers help enterprises build cloud-agnostic pipelines that stay portable and maintainable as their cloud footprints shift.
The Zenus engagement shows this in practice: a fully automated transformation and testing pipeline built on dbt, deployed on Google Cloud infrastructure, with version control and automated testing to catch data problems before they reach end users.
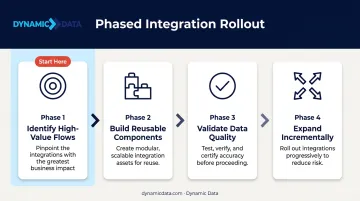
Plan a Phased Rollout Starting with Highest-Value Flows
Attempting full-enterprise integration simultaneously is how projects stall. A more practical approach:
- Identify the two or three integration points causing the most analytical friction or business risk
- Build reusable pipeline components — source connectors, transformation logic, quality checks — that apply to future flows
- Validate data quality at each stage before expanding to the next integration
- Expand incrementally, carrying lessons from each phase forward
Dynamic Data took this exact approach with Pima Solar's fragmented data problem: connecting three disconnected measurement platforms by defining a shared user identifier across all three, creating full visibility of the customer journey without rebuilding their infrastructure.
Governance, Security, and Data Quality in Multi-Cloud Integration
Embed Governance from Day One
Define data ownership, lineage tracking, and access policies before building pipelines. Assign stewardship for each data domain and establish a data catalog that makes integrated assets discoverable across teams — regardless of which cloud hosts them.
Gartner expects active metadata adoption to grow 70% by 2027, with organizations that invest in metadata management spending up to 40% less on data management than those without formal practices.
Security Fundamentals That Span Cloud Boundaries
Non-negotiable controls for any multi-cloud integration layer:
- Encrypt data in transit (TLS 1.2/1.3) and at rest (AES-256) across every cloud boundary
- Enforce role-based access controls consistently — not just within a single cloud environment
- Log every data movement event, particularly at integration points between clouds
GDPR, HIPAA, and SOC 2 all require demonstrable controls at the data movement layer — not just at storage. Retrofitting these controls after pipelines are live typically costs three to five times more than designing for compliance from the start.
Data Quality at the Point of Entry
Validate, standardize, and flag anomalies as data enters pipelines rather than cleaning it downstream. Bad data that clears ingestion will propagate across every connected system — where tracing and correcting it becomes far more costly.
Practical quality controls to enforce at ingestion:
- Schema validation to reject or quarantine records that don't match expected structure
- Format standardization to align date, currency, and ID formats before records enter the warehouse
- Automated data tests (for example, within dbt pipelines) that catch anomalies before they surface in production dashboards
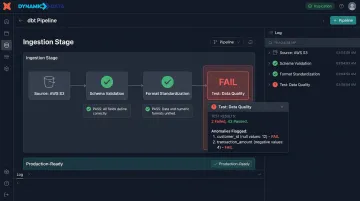
Dynamic Data builds these checks directly into client dbt pipelines, catching data problems before they reach end users rather than after a dashboard flags something wrong.
Frequently Asked Questions
What is enterprise data integration?
Enterprise data integration connects all core business systems — including ERP, CRM, analytics platforms, data warehouses, and cloud applications — into standardized, governed pipelines. The goal is reliable, consistent data flow that supports decision-making at scale — not fragile point-to-point connections managed in isolation by individual teams.
What is multi-cloud integration?
Multi-cloud integration coordinates data flows across two or more public cloud providers (AWS, Azure, Google Cloud), often alongside on-premises systems. It uses standardized pipelines and governance frameworks to eliminate silos and create a unified data environment despite provider-specific APIs and tooling differences.
What are the biggest challenges of multi-cloud data integration?
The five most common challenges are: data residency and regulatory constraints on cross-border data movement, API and protocol inconsistency across providers, cross-cloud egress costs and latency, schema and identity conflicts between systems, and limited pipeline observability when workloads span multiple cloud environments.
How does data governance work across multiple clouds?
Effective multi-cloud governance requires centralized ownership policies, lineage tracking across cloud boundaries, and role-based access controls applied consistently at the integration layer. A unified data catalog ensures assets are discoverable regardless of which cloud hosts them. Retrofitting governance onto existing pipelines costs significantly more than building it in from the start.
Which integration pattern is best for multi-cloud environments?
No single pattern fits every use case. Common approaches include:
- ETL/ELT for batch analytics workloads
- API-based and event-driven patterns for real-time requirements
- Data virtualization where data movement isn't permitted
- CDC (change data capture) for continuous synchronization
Most mature strategies combine two or three of these based on latency, volume, and compliance requirements.
How does multi-cloud data integration support AI and ML initiatives?
AI and ML models require continuous, clean, and unified data inputs. A multi-cloud integration layer ensures training data, feature stores, and inference pipelines draw from a single trusted source — regardless of which cloud hosts each component. Without it, teams spend more time reconciling inconsistent data than building models — and AI initiatives stall before reaching production.


