
Introduction
For most organizations, the problem isn't a lack of data — it's that the data can't talk to each other. Customer records live in one CRM, financial data in an ERP, marketing metrics scattered across cloud apps, and operational data buried in legacy databases. The data exists, but it's fragmented, inconsistent, and nearly impossible to analyze as a whole.
According to IDC, 81% of IT leaders cite data silos as a major barrier to digital transformation, and Google Cloud's 2024 Data and AI Trends Report found that only 44% of organizations are fully confident in their data quality.
Without a deliberate plan for connecting data, teams end up solving the same problem in different ways — producing conflicting metrics and eroding trust in the numbers.
What follows is a practical guide to building a data integration strategy that holds: core techniques, four strategic approaches, a step-by-step framework, and the pitfalls that derail even well-resourced teams.
Key Takeaways
- A data integration strategy is a structured plan for unifying data from disparate sources into consistent, accessible, and trustworthy information
- Core techniques include ETL/ELT, API-based integration, CDC/streaming, and data virtualization, each suited to different latency and volume needs
- The four strategic approaches are centralized, federated, hybrid, and cloud-based integration
- Governance, data quality, and clear ownership matter as much as the technology you choose
- Build iteratively, starting with high-impact use cases — big-bang implementations rarely deliver
What Is a Data Integration Strategy (and Why It Matters)?
A data integration strategy is the structured plan that determines how an organization collects, connects, transforms, and delivers data from multiple sources. It covers tools, architectural approaches, governance standards, and team ownership, not just the pipelines themselves.
Without that plan, integration becomes reactive. Different teams solve the same data problem independently, producing conflicting metrics, duplicated pipelines, and growing technical debt. Gartner estimates poor data quality costs organizations an average of $12.9 million per year — much of that stems from fragmented, ungoverned integration built up ad hoc over time.
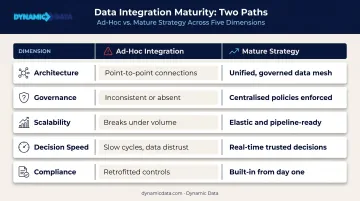
Mature Strategy vs. Ad-Hoc Integration
| Ad-Hoc Integration | Mature Strategy | |
|---|---|---|
| Architecture | Point-to-point connections | Centralized or federated design |
| Governance | Inconsistent or absent | Defined ownership, contracts, lineage |
| Scalability | Breaks as data volumes grow | Designed to scale incrementally |
| Decision speed | Slow — teams distrust data | Fast — single source of truth |
| Compliance | Retrofitted after the fact | Embedded from the start |
A mature strategy doesn't require solving everything upfront — but it does require a clear starting point. Dynamic Data works with clients across SaaS, IoT, and construction sectors, beginning each engagement by mapping available data sources and processing requirements before any architecture decisions are made. That discovery step is what separates intentional design from pipelines that have to be rebuilt six months later.
Core Data Integration Techniques Every Strategy Should Consider
ETL vs. ELT
These two approaches handle the same problem — moving and transforming data — but in a different order, which matters considerably depending on your architecture.
ETL (Extract, Transform, Load) processes data in a separate transformation layer before it reaches the target system. Data is validated and shaped to match business rules before storage.
- Best for: Regulated industries (healthcare, financial services) requiring pre-storage validation, or complex transformations with strict quality controls
- Limitations: Transformation bottlenecks at scale; pipeline fragility when source schemas change; batch latency
ELT (Extract, Load, Transform) loads raw data into the target system first (typically a cloud data warehouse like Snowflake, BigQuery, or Databricks ) then transforms it in place using the warehouse's compute.
- Best for: Cloud-native architectures where analysts own transformation logic, including iterative modeling workflows with tools like dbt
- Limitations: Raw data quality issues can propagate if governance is weak; warehouse compute costs scale with transformation volume
Dynamic Data's team includes certified dbt developers who implement ELT architectures using dbt for transformation automation, version control, and end-to-end testing — as demonstrated in their work with Zenus, where they built a fully automated transformation and testing pipeline on Google Cloud.
API-Based and Streaming Integration
API-based integration connects SaaS platforms and cloud services where direct database access isn't available. REST dominates at 93% adoption according to Postman's 2025 State of the API Report, with webhooks used by 50% of organizations for event-driven, lower-latency data delivery compared to polling-based approaches.
Change Data Capture (CDC) reads database transaction logs to capture row-level changes (inserts, updates, and deletes) in near real time without querying the source system directly. Tools like Debezium and AWS DMS handle this for most major databases. Streaming platforms like Kafka distribute these change events to multiple downstream consumers, making CDC well-suited for use cases where data staleness directly affects business outcomes.
Data virtualization creates a logical query layer over multiple source systems without physically moving data. It's useful when compliance or data residency rules prevent consolidation, or when ad-hoc cross-system analysis is needed without building dedicated pipelines. Performance, however, degrades for high-volume analytics — virtualization works best as a complement to physical integration, not a replacement.
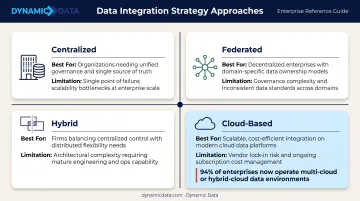
The Four Main Data Integration Strategy Approaches
No single integration architecture fits every organization. The right approach depends on your compliance requirements, team structure, data volumes, and how far along your cloud adoption is.
Centralized integration routes all data into a single repository — a data warehouse or data lake. This enables uniform governance, consistent reporting, and simplified access control.
- Best for: Finance, healthcare, and organizations prioritizing BI standardization and compliance
- Limitation: Can become a bottleneck as data volumes grow and teams need more autonomy
Federated integration keeps data in decentralized source systems while a unified virtual layer provides a consistent view. Each source retains ownership and governance of its data.
- Best for: Multinational enterprises with strict data residency requirements
- Limitation: Query performance depends on source system availability and capacity
Hybrid integration combines centralized and federated elements. Some datasets are consolidated for analytics; others remain distributed for compliance or operational reasons.
- Best for: Large enterprises managing legacy on-premises systems alongside modern cloud applications
- Limitation: Requires careful governance to avoid inconsistency between centralized and distributed datasets
Cloud-based integration uses cloud infrastructure, iPaaS tools, and cloud-native ETL/ELT to manage integration with on-demand scaling and lower infrastructure overhead. The iPaaS market grew 23.4% to $8.5 billion in 2024, per Gartner, with MuleSoft, Oracle, Informatica, SAP, and Boomi holding a combined 57.7% market share.
- Best for: Companies expanding globally or actively migrating workloads to the cloud
- Limitation: Vendor lock-in and ongoing subscription costs can increase over time
How to Build a Data Integration Strategy: A Step-by-Step Framework
Step 1 — Assess Your Current Data Landscape
Catalog all data sources: on-premises systems, SaaS applications, cloud services, and legacy databases. Document their formats, update frequencies, volumes, and business owners. Identify where data is siloed, inconsistent, or inaccessible.
This assessment shapes every downstream decision. Skipping it means building pipelines without knowing what you're connecting — a reliable way to create technical debt immediately.
Step 2 — Define Goals Tied to Business Outcomes
Start with questions, not tools:
- What decisions need better data?
- What reporting latency is acceptable — sub-second, hourly, or daily?
- Are there compliance requirements that constrain architecture?
- What's the single highest-value integration to deliver first?
Tie integration goals to concrete business outcomes: a unified customer view, real-time inventory visibility, automated financial reporting.
When Dynamic Data worked with Pima Solar, the challenge was connecting three unrelated platforms — CallFire, Go High Level, and JobNimbus — to trace the complete user journey from first call to closed sale. That clarity on the business outcome eliminated weeks of scope ambiguity and pointed directly to the right technical approach.
Step 3 — Match Techniques and Tools to Requirements
Map use cases to techniques using these criteria:
| Requirement | Recommended Technique |
|---|---|
| Sub-second latency | CDC + streaming (Kafka, Flink) |
| Hourly batch analytics | ELT (dbt + cloud warehouse) |
| SaaS app connectivity | API-based (REST/webhooks) |
| Compliance/residency constraints | Data virtualization or federated |
| Complex pre-load validation | ETL |

Avoid defaulting to a single technique for all use cases. Most mature organizations use a combination. Evaluating 35+ platforms without prior experience often leads to either over-built architectures or tools that don't scale — a data partner with cross-platform expertise can compress that selection process significantly.
Step 4 — Build Governance Into the Architecture From the Start
Define data ownership before writing a single pipeline. Four governance layers need to be in place before the first pipeline runs:
- Metadata management — cataloging, lineage tracking, and business glossaries
- Data quality standards — contracts between teams and validation rules at ingestion
- Access controls — least-privilege permissions at every pipeline stage
- Compliance checkpoints — GDPR, CCPA, and HIPAA requirements embedded in design, not bolted on afterward
Adding governance after pipelines are built is costly and error-prone. The time to establish it is before the first pipeline runs.
Step 5 — Implement Iteratively and Monitor Continuously
Start with high-impact, well-scoped use cases rather than enterprise-wide integration. Once those initial pipelines are live, instrument them with three monitoring layers:
- Freshness monitoring — alert when data stops arriving on schedule
- Volume checks — detect unexpected drops or spikes in record counts
- Error alerting — surface failures before downstream teams notice
Apply DataOps practices — version control, automated testing, and CI/CD for pipelines. Dynamic Data's Zenus engagement embedded version control and automated testing from day one, catching issues before they reached end users. As source systems change and requirements shift, that foundation is what keeps pipelines reliable rather than becoming a maintenance burden.
Common Challenges and How to Overcome Them
Challenges That Derail Data Integration Projects
Data quality tops the list of integration obstacles. According to dbt Labs' 2024 State of Analytics Engineering report, 57% of data professionals cite poor data quality as their chief challenge — up from 41% in 2022. The fix: build validation and cleansing rules at the point of ingestion, and establish data contracts between teams so quality expectations are explicit before data moves.
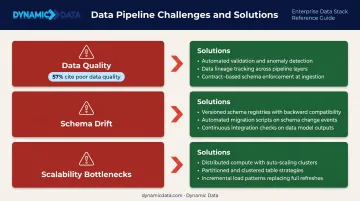
Schema drift and change management breaks pipelines when source systems update without warning. Mitigate with:
- Schema registries that track structural changes
- Automated drift detection in pipeline monitoring
- Flexible parsing logic rather than rigid field-by-field mappings
Scalability bottlenecks tend to appear only under real load. Design for incremental loading from the start:
- Process only changed data, not full reloads
- Push transformations to where the data lives
- Use auto-scaling cloud infrastructure to absorb spikes without manual intervention
Organizational and Security Challenges
Technical fixes only go so far. Organizational gaps are just as likely to derail a project after launch.
Unclear ownership is where integrations most often stall. Define a clear operating model: who monitors logs, who resolves failures, and who maintains transformations. When internal capability is limited, embedding experienced data engineers — as Zenus found when Dynamic Data's team became integral to their product development — closes skill gaps faster than building that expertise in-house.
Security and compliance complexity increases as data moves across more systems. Apply these controls regardless of industry:
- Encryption in transit and at rest for all pipelines
- Least-privilege access enforced at every pipeline stage
- Compliance requirements (GDPR, CCPA, HIPAA) treated as design inputs, not sign-off steps
Best Practices for a Long-Term, Scalable Strategy
Design for flexibility, not perfection. Build modular, composable pipelines that can be updated independently. A strategy that adapts to new sources without full rebuilds outlasts one optimized only for today's data landscape.
Treat metadata as a strategic asset. Invest in cataloging, lineage tracking, and business glossaries early. Gartner identifies metadata management as the backbone of data discovery, documentation, and lineage tracking. Organizations that build this infrastructure early find it far easier to automate integration workflows and onboard AI-driven tooling later.
Track Integration Health with KPIs
Define clear metrics so integration health is visible across the organization — not just to engineering. Track:
- Pipeline failure rates and mean time to resolution
- Data freshness against defined SLAs
- Time-to-integrate for new data sources
- Downstream data quality scores
Share these metrics with both technical teams and business stakeholders. A dashboard that shows a rising pipeline failure rate — visible to a product manager, not just a data engineer — turns a slow-building problem into a conversation before it becomes a crisis.
Frequently Asked Questions
What are the 5 steps of the ETL process?
Extract data from source systems, validate and cleanse it, transform it to match the target schema and business rules, load it into the destination system, then verify and monitor the load for errors or anomalies. In practice, steps two and three often overlap in most ETL platforms today.
What are the techniques of data integration?
The most common techniques are ETL, ELT, API-based integration, data virtualization, Change Data Capture, data warehousing, and streaming integration. The right choice depends on your latency requirements, data volume, and compliance constraints.
What are the 4 types of system integration?
The four main types are:
- Data-centric: moving and transforming data between systems
- Event-centric: streaming events between producers and consumers
- Application-centric: invoking functionality across applications via APIs or middleware
- Point-to-point: direct connections between systems, common in simpler or legacy environments
What is the difference between ETL and ELT?
ETL transforms data before loading it into the destination — useful when strict quality controls are required pre-storage. ELT loads raw data first and transforms it inside the target system, typically a cloud data warehouse, offering more flexibility and speed for modern analytics workloads.
What are the biggest challenges in data integration?
Data quality inconsistencies across sources, schema changes breaking pipelines, performance bottlenecks at scale, security and compliance requirements, and unclear pipeline ownership. Most can be mitigated with upfront governance design rather than addressing them reactively.
How do I choose the right data integration strategy for my business?
Start by defining your latency requirements, data volumes, and compliance constraints. Map those to the appropriate technique and strategic approach: centralized, federated, hybrid, or cloud-based. If internal capability is limited, working with a specialist team usually gets you to production faster and with fewer pipeline failures than a first internal build.


