
Introduction
Most organizations start their AI journey the same way: evaluate models, pick a platform, assemble a pilot team. Three months later, they hit a wall — and that wall turns out to be their own data warehouse.
The numbers are stark. According to Gartner, at least 50% of generative AI projects were abandoned after proof of concept, with poor data quality, unclear business value, and escalating costs cited as the primary causes. A separate Gartner survey found that only 48% of AI projects ever reach production.
The question worth asking before you spend another dollar on model development: is your data actually ready?
This post covers what data readiness actually means, how a structured assessment works, and what a phased AI adoption roadmap looks like when it's built from the data up. It also covers what to look for in a consulting partner who can execute the plan, not just deliver one.
Key Takeaways
- 50% of GenAI pilots are abandoned after proof of concept — and data problems, not model problems, are almost always the cause
- Data readiness spans quality, governance, infrastructure, and unstructured data — far beyond simply "cleaning" what you have
- A proper AI readiness assessment produces a gap-by-gap scorecard and cost estimates, not a slide deck
- Roadmap phases must follow a defined sequence: business problem, data foundation, pilot, production, then scale
- Look for a consultant who can assess and remediate your data gaps, not just document them
Why AI Initiatives Stall: The Data Problem No One Wants to Address
There's a pattern that repeats across industries. An organization launches an AI pilot with genuine enthusiasm. Early demos look promising. Leadership gets excited. Then the project quietly stalls — unable to scale, unable to get reliable outputs, eventually shelved.
This is what's commonly called "pilot purgatory." The AI worked in a controlled demo environment with curated data. It failed in production because production data is messier, siloed, and far less governed than anyone admitted upfront.
The Real Culprit
Organizations frame AI failure as a technology problem when it's almost always a data problem.
- Models fed incomplete or inconsistent records produce outputs no one trusts
- Data locked in departmental silos can't be accessed cross-functionally
- Governance gaps mean there's no agreed-upon definition of something as basic as "active customer"
- Unstructured data — emails, call recordings, PDFs — sits untapped because no pipeline ingests it

These aren't edge cases. They're the norm in organizations where data infrastructure hasn't kept pace with AI ambition.
The Business Cost
Gartner research puts the average annual cost of poor data quality at $12.9 million per organization. IBM's more recent figures are even sharper: over 25% of organizations estimate poor data quality costs them more than $5 million annually, with 7% reporting losses of $25 million or more.
Fixing data problems after a model is already in development costs significantly more than addressing readiness before the build begins. Yet most organizations don't discover the gaps until they're already deep into development — which is exactly when they're most expensive to resolve.
What Data Readiness Really Means for AI Adoption
Data readiness describes how well an organization's data is accurate, accessible, governed, and structured so that AI systems can reliably learn from it and act on it. Most organizations exist somewhere along this spectrum — and most don't know exactly where they stand until a project stalls.
One underappreciated dimension is the unstructured data problem. IBM estimates that approximately 80% of enterprise data is unstructured — call recordings, emails, PDFs, chat logs, documents. That volume represents a genuine readiness gap: modern pipelines can ingest, classify, tag, and make this data usable for AI, but only if that work is planned for and resourced.
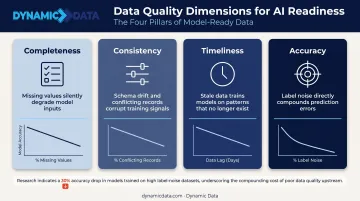
Data Quality
The four dimensions that matter most:
- Completeness — Are the fields your models need actually populated?
- Consistency — Does "revenue" mean the same thing in your CRM and your data warehouse?
- Timeliness — Is the data fresh enough for the decisions you're asking AI to support?
- Accuracy — Do records reflect ground truth, or have errors accumulated over time?
Even small percentages of missing or inconsistent records compound quickly at model scale. A 2022 peer-reviewed study found that SVM classification accuracy fell by over 30% when random label noise increased from 10% to 50% — a concrete illustration of how data quality directly degrades model performance.
Data Governance
Governance determines who owns data, what it means, how it flows, and who can access it. AI amplifies whatever governance gaps already exist. If your sales team and finance team define "churned customer" differently, your churn prediction model will inherit that ambiguity.
Gartner projects that by 2027, 60% of organizations will fail to realize expected AI value due to incohesive data governance frameworks. Governance is infrastructure, not overhead. Treating it as an afterthought is one of the most consistent ways AI investments underdeliver.
Infrastructure and the Semantic Layer
Data that lives in spreadsheets, disconnected SaaS tools, or legacy databases can't reliably feed an AI system. But infrastructure readiness goes beyond just moving data into a warehouse.
A semantic layer — implemented through platforms like dbt, Snowflake, or Looker — creates a shared "company language" that maps raw data fields to consistent business definitions. It ensures that AI models, BI dashboards, and human analysts are all drawing from the same source of truth. Dynamic Data's analytics engineers build semantic layers as part of their data foundation work, typically using dbt and Snowflake to create governed, reusable metric definitions before any model development begins.
How a Consultant Assesses Your Data Readiness
A genuine data readiness assessment is not a questionnaire. It involves workshops with domain leads, a data inventory audit, pipeline and infrastructure review, governance gap analysis, and quality checks against the specific use cases under consideration. The output is specific and actionable — grounded in your actual infrastructure, not boilerplate recommendations.
Five Questions Every Organization Should Answer First
Before building any AI roadmap, leadership should be able to answer these:
- Can we access the data our priority AI use cases require, in real or near-real time?
- What percentage of that data meets quality standards for those use cases?
- Do we have documented ownership and data lineage for key datasets?
- Can our infrastructure handle AI workload volume and variety?
- Have we mapped compliance requirements for each planned use case?
Most organizations discover they can't confidently answer two or three of these. That gap is the assessment's starting point.
What a Maturity Scorecard Delivers
The primary deliverable of a data-led assessment is a maturity scorecard: a gap-by-gap breakdown of where data infrastructure, quality, and governance currently stand, paired with a prioritized remediation plan and realistic cost and timeline estimates.
This scorecard does something a strategy slide deck cannot. Stakeholders can see precisely what it will take to reach AI readiness — and what it will cost — before any budget goes toward model development.
That level of specificity requires genuine technical depth. Dynamic Data conducts these assessments hands-on, working directly inside:
- dbt pipelines and data lineage
- Data warehouse architecture (Snowflake, BigQuery, Databricks)
- BI integration and reporting layers
- Governance frameworks and compliance mapping
The team's dbt Certified Developers and analytics engineers produce findings that translate directly into an actionable roadmap — not a presentation that requires another engagement to operationalize.
Building a Phased AI Adoption Roadmap
Phase 1: Business Problem and Use Case Alignment
Every AI roadmap should start with a business problem, not a model choice. The consultant's role in this phase is to facilitate structured workshops that surface 3–5 priority use cases — each with a clear owner, a measurable outcome, and a preliminary estimate of data requirements.
Prioritization criteria typically include: business impact, data availability, implementation complexity, and time-to-value. Use cases that score well on impact but poorly on data availability become roadmap dependencies, not immediate pilots.
Phase 2: Data Foundation and Infrastructure
Before any model development begins, close the gaps identified in the readiness assessment. This phase includes:
- Pipeline development and optimization for AI workload requirements
- Governance policy activation: ownership assignments, lineage documentation, access controls
- Semantic layer build to ensure consistent metric definitions across downstream AI and BI systems
- Data quality remediation for priority datasets
This is where most organizations underinvest — and later pay for it in rework. McKinsey estimates that as much as 90% of failures in ML development come from poor productization rather than poor models, and inadequate data foundations are the root cause of most productization failures.
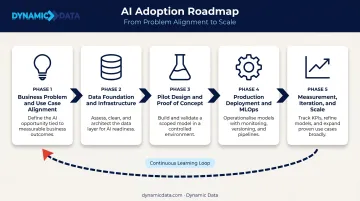
Phase 3: Pilot Design and Proof of Concept
A well-scoped pilot answers three questions before a single model is trained:
- Technical feasibility: Can the system handle the data volume and latency requirements?
- Data sufficiency: Is the training data representative, clean, and available at scale?
- Integration viability: Can outputs connect to the systems where decisions actually get made?
Success criteria must be defined in advance and tied to business metrics, not model accuracy in isolation. Pilot scope should be narrow enough to yield quick, clean results — but representative enough that findings generalize. Too broad, and you never get a clear signal. Too narrow, and results don't transfer.
Phase 4: Production Deployment and MLOps
The transition from pilot to production is the most commonly skipped planning step. What must be in place:
- Automated data pipelines that feed the model consistently at production volume
- Model monitoring for drift and performance degradation
- Retraining triggers and version control
- Human-in-the-loop review processes for high-stakes outputs
All of these need to be designed into the roadmap from Phase 2 — not retrofitted after the model is already live. Gartner found it takes an average of 8 months to move from prototype to production — teams that skip MLOps planning extend that timeline further.
Phase 5: Measurement, Iteration, and Scale
KPIs that signal a roadmap is working:
- Time-to-first-production-model against plan
- Adoption rates among intended business users
- Business impact metrics: cost savings, efficiency gains, revenue lift
- Data quality improvement over time as remediation takes hold
- Model performance vs. baseline and drift monitoring status
Each phase should generate feedback that informs earlier-stage assumptions. Production behavior often reveals data gaps that weren't visible during piloting — a good roadmap builds in feedback loops to catch and address these.
What Separates a Data-Ready Consultant From a Strategy-Only Firm
Strategy-only firms deliver frameworks. A data-ready consultant can do both — assess and remediate data infrastructure, build the pipelines, and then build the AI on top of it. When a project hits an unexpected data gap, that difference determines whether the engagement stalls or moves forward.
What to Look For
- dbt Certified Developers and analytics engineers on the team, not just strategists
- Documented experience with data governance, lineage, and pipeline architecture
- The ability to provide cost and timeline estimates tied to specific data gaps
- A team that includes data engineers capable of executing remediation, not just documenting it
Dynamic Data's team holds dbt Certified Developer credentials and works across Snowflake, BigQuery, Databricks, and dbt to assess and build the data foundations that AI systems require. With expertise across 35+ platforms, assessments reflect your environment rather than a preferred vendor stack.
Four Red Flags When Evaluating Consultants
- Cannot discuss data lineage, pipeline architecture, or governance in concrete terms
- Presents a one-size-fits-all AI framework regardless of your data maturity
- Recommends specific AI tools before completing a data readiness assessment
- Has no engineering capability in-house and relies entirely on subcontractors for implementation

Once you've spotted the red flags, direct questions will confirm — or disqualify — a firm quickly.
Questions Worth Asking
- What percentage of your engagements require data remediation before model development?
- Can you show me a maturity scorecard from a comparable engagement?
- What does your team's data engineering capability look like?
- How do you handle governance for regulated data?
A firm with genuine data engineering depth will answer these specifically. Vague responses — or pivoting back to strategy decks — tell you what you need to know.
Frequently Asked Questions
What does "data readiness" mean in the context of AI adoption?
Data readiness is the state in which an organization's data is accurate, accessible, governed, and structured enough for AI systems to reliably learn from it and act on it. Most organizations discover significant gaps — in quality, lineage, or governance — only after piloting AI and encountering production failures.
How long does it take to build an AI adoption roadmap?
A focused data readiness assessment and roadmap scoping typically takes 2–6 weeks. A full roadmap from discovery through first production model spans 6–12 months, depending on data maturity, use case complexity, and required foundation work.
What are the most common data problems that block AI implementation?
The most frequent blockers: siloed data that can't be accessed cross-functionally, poor data quality (incomplete, inconsistent, or stale records), lack of documented ownership and governance, and unstructured data that hasn't been captured or tagged for use.
How do I know if my business needs an AI adoption roadmap consultant?
Clear signals include: AI pilots that can't scale to production, repeated data quality surprises during model development, no clear owner for AI initiatives, or uncertainty about which use cases will deliver ROI relative to their data readiness cost.
What is the difference between an AI strategy and an AI adoption roadmap?
Strategy defines the vision — which problems to solve, which outcomes to target, what governance principles to follow. A roadmap is the execution plan — what to build, in what order, with what data and infrastructure requirements and measurable milestones at each phase.
How does data governance affect AI model performance?
Governance ensures models are trained on accurately defined, consistently structured, and compliant data. Without it, models produce unreliable outputs, erode user trust, and expose the organization to regulatory risk — making governance a prerequisite for AI outputs that are actually safe to act on.


