
Manual integration approaches can't keep pace. Pipelines break silently when source systems change. Batch jobs create lag. Schema updates trigger emergency fixes that consume engineering capacity for days.
AI data integration offers a different path: intelligent, adaptive pipelines that automate mapping, transformation, and quality checks in real time — turning fragmented data into a unified, decision-ready asset. This article covers what AI data integration is, why legacy approaches fail, how AI transforms each stage of the process, and what it takes to get started.
Key Takeaways
- AI data integration uses ML and automation to connect, transform, and unify data from disparate sources, replacing manual scripting with self-learning pipelines
- Legacy ETL breaks at scale: it can't handle schema changes, data volume growth, or real-time demands
- AI automates the most error-prone steps — schema mapping, cleansing, entity resolution, and anomaly detection
- Key benefits: faster insights, higher data quality, reduced engineering overhead, and a single source of truth
- Getting started means mapping your current data sources, setting clear goals, and working with a team that has hands-on implementation experience
What Is AI Data Integration?
AI data integration is the practice of using machine learning and natural language processing to automate how data is connected, transformed, and delivered from multiple sources into a unified, analysis-ready view.
Traditional integration depends on hand-coded pipelines, manual field mapping, and fixed transformation rules. When a source system changes its schema, those pipelines break. When data volumes spike, they slow. When a new tool gets added, someone has to write another custom connector. AI-powered integration removes that fragility by adapting to change rather than requiring manual intervention each time.
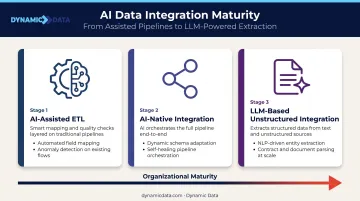
The Three Core Forms
| Form | What It Does |
|---|---|
| AI-assisted ETL | Traditional pipelines enhanced with smart mapping, anomaly detection, and quality checks |
| AI-native integration | AI orchestrates the full pipeline — from discovery and mapping to monitoring and error recovery |
| LLM-based unstructured integration | Large language models extract structured data from documents, PDFs, emails, and other text sources |
Each form serves a different level of organizational maturity. Most companies start with AI-assisted ETL and evolve toward AI-native as their pipeline complexity and data volume grow.
What makes this matter beyond the technical mechanics: every downstream output — ML models, dashboards, business decisions — is only as reliable as the data feeding it. Errors introduced at the pipeline level compound through every analysis built on top of it.
Why Traditional Data Integration Falls Short
The problems with legacy data integration aren't theoretical — they show up in engineering backlogs, stale dashboards, and strategy meetings where two teams cite different numbers.
According to a Fivetran/Wakefield Research study, data engineers spend 44% of their time manually building and managing pipelines — translating to an average annual cost of $519,552 per company. That same study found 80% of data leaders have had to rebuild pipelines after deployment, with 39% doing so regularly.
These aren't edge cases — they're the predictable outcome of infrastructure built for a simpler, slower data environment.
Three Core Breakdowns
Schema fragility. Source systems change constantly — API updates, CRM migrations, new fields added without notice. Rigid pipelines break silently and often go undetected until someone notices the numbers look wrong.
Batch-based latency. Most traditional pipelines run on schedules — hourly, nightly, weekly. Only 13% of companies get value from newly collected data within minutes or hours; 76% wait days or up to a week. By then, the insight is history.
Compounding data quality debt. Inconsistent formats, duplicate records, and missing values accumulate across pipelines. The result: 85% of data leaders report their company lost money from decisions made with old or error-prone data. That erosion of trust is often harder to fix than the pipelines themselves.
Layer in SaaS sprawl — companies now run an average of 106 applications, each potentially requiring its own custom connector — and the maintenance burden becomes unsustainable. Data teams end up firefighting instead of building. That's the gap AI-driven integration is designed to close.

How AI Transforms the Data Integration Process
AI doesn't just speed up traditional integration — it changes how each stage works.
Automated Schema Mapping
AI scans connected systems to identify available data and its structure, then uses ML models to recommend field mappings between sources. When one system calls it customer_id and another calls it user_key, the model recognizes the match based on data type, content patterns, and semantic similarity.
High-confidence matches are applied automatically. Low-confidence ones get queued for human review, with a confidence score attached. This approach, developed in academic research like the Matchmaker LLM-based schema matching framework, significantly cuts the manual mapping burden while preserving oversight where it matters.
Intelligent Data Cleansing
Rather than waiting for someone to notice a problem, AI continuously monitors incoming data for quality issues:
- Duplicate records across sources
- Inconsistent date formats, currencies, or identifier structures
- Missing required values
- Statistical outliers that signal upstream errors
Standardization rules apply automatically, so data arriving in your warehouse or data lake is clean and consistent before it reaches any analyst or model.
Real-Time Ingestion and Change Data Capture (CDC)
AI-powered pipelines process data as it's generated via event streaming, or capture only incremental changes from source databases using CDC (tracking inserts, updates, and deletes from transaction logs with minimal source-system impact).
Stale data carries real costs. Fraud detection running on yesterday's transactions, inventory that doesn't reflect this morning's shipments, campaign optimization built on last week's conversions — these gaps have measurable consequences.
Confluent's 2024 survey of 4,110 IT leaders found 86% prioritized investment in data streaming, and 63% said streaming platforms significantly fuel AI progress — a clear signal that real-time data infrastructure is becoming a competitive baseline, not a luxury.
Entity Resolution and Deduplication
The same customer might exist as "John Smith" in your CRM, "J. Smith" in your billing system, and "jsmith@email.com" in your marketing platform. ML algorithms identify these as the same real-world entity and merge them into a single "golden record."
This capability (sometimes called record linkage) is what makes a true Customer 360 possible. Without a reliable golden record, every downstream report and model inherits the fragmentation you're trying to fix.
Continuous Monitoring and Anomaly Detection
AI establishes baselines for normal data behavior: typical record counts, value distributions, update frequencies. When actual values fall outside expected ranges, the system flags the deviation automatically.
The alternative is reactive firefighting. Monte Carlo data shows monthly data incidents rose from 59 in 2022 to 67 in 2023, with average detection taking 4+ hours and average resolution taking 15 hours. AI monitoring compresses both dramatically by catching issues at the source, not after someone notices the dashboard looks wrong.

Key Benefits of AI Data Integration
Faster Time-to-Insight
AI removes the lag between data creation and its availability in dashboards. Business leaders get current, unified data rather than waiting for manual report preparation — or worse, receiving a report built on last week's export.
Improved Data Quality and Organizational Trust
When every team — marketing, finance, sales, operations — pulls from the same clean dataset, the "whose numbers are right?" debate disappears. Automated cleansing and validation create a shared source of truth, which is what actually drives confident strategic decisions.
Reduced Engineering Overhead
New integrations that previously took weeks can be deployed in days. Schema changes no longer trigger emergency fixes. Data engineers spend time building ML models and data products instead of patching pipelines — a real productivity gain for engineering teams who are perpetually stretched thin against a growing backlog.
Scalability Without Rebuilds
AI-native pipelines adapt to new data sources, evolving schemas, and growing volumes without requiring full pipeline rebuilds. Adding a new marketing tool, expanding to a new market, or integrating an acquired company's systems can be handled incrementally — days or weeks, not the months a traditional rebuild would require.
Stronger Governance and Compliance Support
AI integration supports governance through automated controls built directly into the pipeline:
- Classifies sensitive data like PII at ingestion
- Maintains end-to-end data lineage across systems
- Enforces access policies without manual intervention
- Flags compliance risks before they reach downstream reports
This is especially relevant for GDPR and CCPA obligations, where Article 30 recordkeeping requirements demand clear documentation of what data exists, where it flows, and who can access it.
AI Data Integration Use Cases Across Industries
AI data integration solves different problems depending on the industry — but the underlying pattern is consistent: disconnected systems create blind spots, and unified data removes them. Here are three areas where that shift is most impactful.
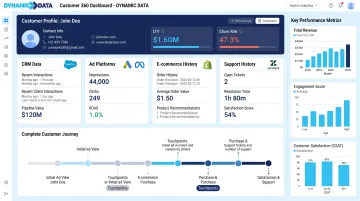
Customer 360 and Marketing Optimization
No single platform holds the complete picture of a customer.
AI integration pulls together CRM records, ad platform data, e-commerce transactions, and support history into a unified customer profile — enabling accurate attribution, personalized marketing, and a complete view of the journey from first touch to repeat purchase.
This is exactly the problem Pima Solar faced before engaging Dynamic Data. They were running three disconnected tools — CallFire for calls, Go High Level for leads, and JobNimbus for sales — with no way to track the full customer journey. After integration, they gained complete visibility from first contact through completed sale, significantly reduced time spent manually identifying users and tracking statuses, and moved off custom Google Sheets entirely. As Jake Martin, Co-founder and CEO, put it: "The dashboards delivered by the Dynamic Data team exceeded my expectations. I was able to get clarity on data I didn't even realize I could get."
Operations, IoT, and Real-Time Infrastructure
Manufacturers, logistics companies, and field services businesses use AI integration to unify their operational data — connecting ERP systems, IoT sensor feeds, and logistics platforms to enable predictive maintenance, live inventory visibility, and demand forecasting.
Dynamic Data's work with Zenus, an IoT company specializing in ethical facial analysis, illustrates the shift from manual to real-time. Zenus had been manually processing and storing data, which prevented them from scaling. Dynamic Data built a Data Warehouse on Google Cloud, created a fully automated transformation and testing pipeline using dbt, and converted their static dashboard into a live, real-time view — with version control and automated testing built in. The co-founder noted that the team's ability to deliver on a compressed timeline was critical to meeting their goals.
Financial Reporting and Business Intelligence
Finance and operations teams use AI-integrated data to replace manual spreadsheet consolidation with governed, always-current datasets. The practical impact shows up quickly:
- Recurring reports run automatically — no manual refresh required
- Reconciliation time drops when source data is unified and validated
- Leadership gets live performance dashboards instead of stale weekly exports
- Strategic planning relies on data that reflects today, not last Tuesday
The goal isn't just speed. It's replacing a process that's inherently error-prone and always slightly out of date with one that actually supports real decisions.
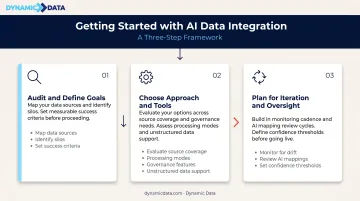
How to Get Started with AI Data Integration
Step 1: Audit Your Data Ecosystem and Define Clear Goals
Map where your most valuable data lives. Identify the silos creating the most friction. Define what success looks like — faster reporting, a unified customer view, fewer manual handoffs. This scoping exercise determines which integrations to prioritize and prevents over-engineering from the start.
Dynamic Data's AI Strategy & Consultation services help organizations build a clear roadmap, identify high-impact use cases, and choose the right technologies before a line of code is written.
Step 2: Choose the Right Approach and Tools
When evaluating integration approaches, consider:
- Source coverage — does the platform support your existing data sources out of the box?
- Processing modes — does it handle both real-time streaming and batch, or only one?
- Governance features — built-in lineage, access controls, and PII classification
- Structured and unstructured data — can it handle PDFs, emails, and documents alongside database records?
Organizations with complex or custom data stacks frequently benefit from working with an experienced data partner rather than relying solely on off-the-shelf tooling. The right platform fits your data architecture — not the reverse.
Step 3: Plan for Iteration and Human Oversight
Successful AI data integration isn't a one-time deployment. Ongoing success depends on:
- Monitoring pipelines for drift, failures, and anomalies
- Reviewing AI mappings after source system changes
- Establishing confidence thresholds — what gets auto-accepted versus flagged for human review
Dynamic Data's certified dbt developers and analytics engineers — proficient in Snowflake, BigQuery, and Python — build and maintain modern AI-integrated data stacks built for scale. Ongoing support comes standard after initial deployment.
Frequently Asked Questions
What is the difference between AI data integration and traditional data integration?
Traditional integration relies on manually coded pipelines and fixed rules that require human intervention every time a source system changes. AI data integration uses ML to learn data patterns, automate mapping and transformation, and self-adapt to schema changes, reducing maintenance burden and improving accuracy over time.
What are the main types of AI data integration?
The three primary forms are AI-assisted ETL (traditional pipelines with AI-enhanced mapping and quality checks), AI-native integration (platforms where AI orchestrates the full data pipeline), and LLM-based unstructured integration (using large language models to extract structured data from documents, emails, and PDFs).
What AI techniques are most commonly used in data integration?
Core techniques include machine learning for pattern recognition and automated field mapping, NLP for understanding text and unstructured data, and deep learning for complex data patterns. Real-time processing models handle event-driven ingestion and anomaly detection.
What are the biggest challenges of AI data integration?
Data quality in source systems remains foundational: AI amplifies existing issues rather than fixing them. Legacy system compatibility requires careful planning. Transparency also matters: teams need to audit and override AI-driven mapping decisions, especially for compliance-sensitive data.
How long does it take to implement AI data integration?
A focused integration connecting 3–5 core systems can be operational in weeks. Enterprise-wide deployments involving legacy systems and complex governance typically take several months. Starting with a high-impact use case and expanding iteratively is almost always the right call.
How do I know if my business is ready for AI data integration?
Clear readiness signals include:
- Your team spends significant time on manual data preparation
- Data lives in multiple disconnected systems
- Reporting inconsistencies are slowing decisions
- You're planning ML models and need a clean, unified data foundation


