
Introduction
Financial institutions sit on some of the richest datasets in existence: transaction histories, behavioral signals, payment flows, customer lifecycle events. Most of it goes unused.
The reporting tells you what happened last quarter. The dashboards confirm what you already suspected. Meanwhile, fraud tactics evolve faster than rule-based systems can adapt, creditworthy applicants get rejected because their files are thin, and customers quietly disengage weeks before they churn.
The gap isn't data. According to Forrester, 74% of firms want to be data-driven, but only 29% successfully connect analytics to action — and fewer than 10% are advanced in their insights-driven capabilities. For fintech companies, that gap is a competitive liability.
This guide covers what predictive analytics actually means in a fintech context, the model types that matter most, the use cases with the clearest ROI, and the best practices for building a strategy that produces measurable results — not expensive proofs-of-concept.
Key Takeaways
- Predictive analytics shifts fintech teams from backward-looking reporting to forward-looking forecasts that drive proactive decisions
- Three core model types serve distinct purposes: time series for trend forecasting, classification for event categorization, and cluster analysis for behavioral segmentation
- Fraud detection offers the fastest ROI; credit scoring, churn prediction, and cash flow forecasting follow with longer but significant payback horizons
- Data quality, architecture fit, and model monitoring are the three most common failure points in production deployments
- Regulatory explainability requirements are non-negotiable — build them into the model from day one
What Is Predictive Analytics in Fintech?
Predictive analytics in fintech is the application of machine learning algorithms, statistical models, and historical financial data to forecast future outcomes before they occur. Questions like these can't be answered by a dashboard:
- Will this loan default before the borrower misses a payment?
- Is this transaction fraudulent, or just unusual?
- Is this customer showing early signs of churn?
They require models trained to recognize the patterns that precede those outcomes.
The distinction from traditional financial analysis is clear. Conventional BI reporting is backward-looking: it tells you what happened, which cohorts underperformed, where costs ran over. Predictive analytics is forward-looking: it tells you what is likely to happen, at a speed and scale no human analyst can match manually.
The market reflects this shift. The global AI in fintech market is projected to grow at a CAGR of 16.5% through 2030, driven largely by investment in fraud detection, credit risk, and customer intelligence applications. Companies that build predictive infrastructure early gain a compounding advantage: better models require more data, and more data accumulates the longer you stay in production.
The Three Model Types Every Fintech Team Should Know
Most fintech teams operate at the descriptive or diagnostic tier of the analytics maturity spectrum — reports that describe what happened, dashboards that surface why. Competitive advantage starts at the predictive tier and compounds at the prescriptive tier, where models not only forecast outcomes but recommend specific actions.
Three model types form the practical foundation for fintech predictive work:
Time Series Models
Used to forecast trends across a continuous timeline. In fintech, the primary applications are cash flow projection, loan default rates by cohort, and revenue forecasting. These models identify seasonality, growth trends, and cyclical patterns in historical data, then extend those patterns forward.
Classification Models
Sort events or entities into discrete categories: fraud vs. legitimate transaction, high-risk vs. low-risk credit applicant, likely to churn vs. likely to stay. Classification models power most real-time decisioning systems in fintech — and typically deliver the fastest time-to-value for teams just entering predictive work.
Cluster Analysis
Used to group customers or transactions by behavioral similarity, without predefined labels. Cluster models reveal natural segments in your customer base — who behaves like a high-value long-term user, who shows early warning signs of disengagement — enabling targeted interventions rather than one-size-fits-all outreach.
Neural networks and ensemble methods extend these foundations for complex, high-volume problems. But model selection should start with a clearly defined business question — not a technology preference. Pick the prediction problem first; the right model type follows from there.

Key Use Cases: Where Predictive Analytics Delivers the Most Value
Fraud Detection and Prevention
Fraud detection is where predictive analytics shows the fastest, most quantifiable ROI in fintech. Traditional rule-based systems flag transactions against static thresholds — effective for known patterns, blind to novel ones. ML-based systems analyze every transaction against dynamic behavioral baselines, learning continuously from new fraud patterns as they emerge.
The benchmark numbers make the case clearly:
- Revolut's Sherlock system evaluates transactions in under 50 milliseconds, catches 96% of fraudulent transactions, and saved over $3 million in its first year of production
- Danske Bank's deep learning deployment reduced false positives by 60% from a baseline where 99.5% of investigated cases turned out not to be fraud — meaning investigators were chasing legitimate transactions nearly all the time
- Total cost multiplier: For every dollar directly lost to fraud, North American financial institutions spend an additional $3.41 on labor, investigation, and recovery — a $4.41 all-in cost per fraud dollar lost
Prevention pays at multiples of the direct loss figure.
Credit Scoring and Risk Assessment
Traditional FICO-based credit scoring leaves money on the table in two directions: approving applicants who will default, and rejecting applicants who would have paid reliably. Predictive credit models address both by incorporating transaction history, income patterns, spending behavior, and alternative data alongside bureau data.
The performance differential is measurable. BIS research found that ML techniques add 5.3 percentage points to AUROC over traditional models, with non-traditional data contributing an additional 2.2 points — a combined 7.5-point improvement in predictive accuracy for credit risk.
The business case runs in multiple directions:
- Reduced defaults through earlier identification of high-risk applicants
- Expanded addressable market — as of 2020, approximately 7 million U.S. adults remained credit invisible, disproportionately affecting low-income and minority communities who could be served with alternative data models
- Faster decisioning that reduces abandonment in digital lending flows
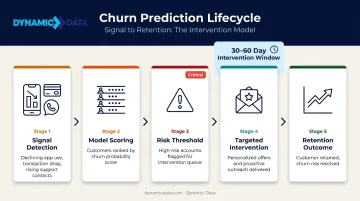
Customer Churn Prediction and Retention
Customers rarely churn without warning. Declining app engagement, reduced transaction frequency, an uptick in support contacts, a missed subscription renewal — these signals appear weeks before a customer cancels. Classification and clustering models can surface those patterns early enough for intervention.
The economics make churn prediction a high-priority investment. A 5% improvement in customer retention can increase profits by 25% to 95%, according to Bain & Company research, and acquiring a new customer costs roughly five times more than retaining an existing one. Even modest retention improvements translate directly to profitability.
The practical model output is a ranked list: customers most likely to churn within a defined window, with the behavioral features driving that score. That list feeds personalized offers, proactive outreach, or product nudges — typically deployed 30–60 days before anticipated churn, while intervention is still actionable.
Cash Flow and Revenue Forecasting
For SMB-focused fintech platforms, cash flow uncertainty is the sharpest operational pain point. Time series models applied to transaction logs, invoice patterns, and seasonal signals replace manual spreadsheet forecasting with continuously updated projections.
JP Morgan's Cash Flow Intelligence deployment at Prysmian shows what that looks like in practice:
- Forecast error rate: under 1%
- Forecasting window: extended from 30 to 91 days (threefold improvement)
- Labor savings: ~$100,000 annually, with manual treasury work cut by 50%
QuickBooks and Xero now ship similar capabilities to SMB users as default product features, raising expectations across the market.
Best Practices for Building a Predictive Analytics Strategy
Best Practice 1 — Define the Business Problem Before the Model
The most common failure mode in fintech analytics is starting with a tool rather than a question. "We should build an ML model" is not a strategy. "We want to reduce payment fraud loss by 20% over the next two quarters" is.
Before evaluating any technology, teams should define:
- The specific decision the model will improve
- Who makes that decision today, and how
- What the measurable success threshold looks like
- What data currently exists to train against
Best Practice 2 — Invest in Data Quality and Governance First
Predictive models are only as reliable as the data they train on. Dirty data doesn't produce uncertain predictions — it produces confidently wrong ones, which is worse.
Before building production-grade models, fintech teams should:
- Audit data completeness across all source systems
- Resolve integration gaps between payment processors, CRM, and core platforms
- Establish data lineage documentation and quality standards
- Define ownership for ongoing data governance
Platforms like Snowflake, BigQuery, and Databricks — combined with transformation layers like dbt — give teams the infrastructure to consolidate fragmented data into clean, model-ready feature sets. Skipping this foundation makes every model downstream unreliable, regardless of how sophisticated the modeling layer is.
Best Practice 3 — Match Architecture to the Use Case
Architecture mismatches are a common source of both performance failures and unnecessary cost.
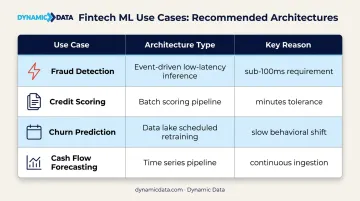
| Use Case | Architecture | Why |
|---|---|---|
| Fraud detection | Event-driven, low-latency inference | Decisions must occur within ~50-100ms during transaction processing |
| Credit scoring | Batch scoring pipeline | Applications can tolerate minutes; training runs can be scheduled |
| Churn prediction | Data lake, scheduled retraining | Behavioral patterns shift slowly; weekly or monthly batch scoring is sufficient |
| Cash flow forecasting | Time series pipeline | Continuous ingestion of transactions, daily model updates |
Building a real-time event-driven system for a use case that only needs nightly batch scoring wastes engineering resources. Deploying batch architecture for fraud detection means making decisions on stale scores — which defeats the purpose.
Best Practice 4 — Build Model Monitoring From Day One
Predictive models degrade over time. Fraud tactics evolve, customer behavior shifts with economic conditions, and seasonal patterns change. A model that performs well at deployment can become unreliable six months later — with no visible warning unless someone is actively watching.
Production ML systems require:
- Accuracy and precision/recall dashboards tracked over time
- Automated alerts when model performance drops below defined thresholds (concept drift detection)
- Scheduled retraining cycles triggered by drift indicators
- Version control and rollback capability
Models are living systems with ongoing maintenance requirements, not one-time deliverables. Budget for them accordingly from the start.
Best Practice 5 — Align Data, Finance, and Compliance from the Start
Predictive analytics in fintech sits at the intersection of technical modeling, financial decision-making, and regulatory constraint. Siloed execution — where data teams build models that compliance reviews after the fact — creates expensive rework cycles and deployment delays.
The most effective teams treat compliance as a design constraint from sprint one, not a gate at the end. This means involving legal and compliance stakeholders early, building audit trails into the model pipeline, and documenting model decisions in formats that regulators can review. Dynamic Data's approach integrates ML engineering with data governance from the outset — so models are built to be both accurate and auditable, rather than retrofitted for compliance after the fact.
Common Implementation Challenges and How to Address Them
Most fintech teams encounter the same three obstacles when moving predictive analytics from concept to production. Knowing where each breaks down — and how to get ahead of it — saves months of rework.
Data Silos and Integration Complexity
Customer data living across payment processors, CRMs, and core banking platforms is the rule in fintech, not the exception. The fix is a centralized data pipeline that normalizes and consolidates streams before model training begins. A typical modern stack looks like:
- Warehousing: Snowflake or BigQuery
- Ingestion: Fivetran or Stitch
- Transformation: dbt
Talent Gaps and Model Interpretability
Building and maintaining production ML models requires specialized skills most fintech teams don't have in-house. Beyond the technical gap, non-technical stakeholders — credit officers, compliance teams, board members — often resist trusting outputs they can't explain, regardless of model accuracy.
Close the talent gap through external partnerships or augmented teams. For interpretability, explainable AI techniques like SHAP values (the most widely adopted approach) present the top contributing factors behind each prediction in plain language, giving stakeholders a clear basis for decisions.
Regulatory Compliance and Model Fairness
The CFPB's 2023 guidance requires that lenders using AI for credit decisions provide specific, accurate reasons for adverse actions; algorithmic complexity is not an acceptable substitute. The EU AI Act classifies credit scoring as a high-risk AI system with explicit transparency and documentation requirements.
These aren't post-launch considerations — they're development constraints. Model documentation, bias testing against protected class proxies, and audit trails need to be built into the pipeline before any model reaches production.
Measuring Success: KPIs for Predictive Analytics in Fintech
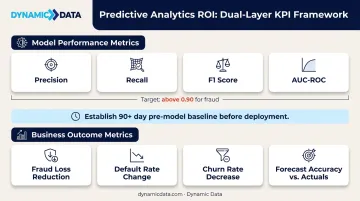
Predictive analytics ROI requires two distinct measurement layers:
Model performance metrics:
- Classification models: precision, recall, F1 score, AUC-ROC (target above 0.90 for fraud detection)
- Forecasting models: RMSE, MAPE, forecast error rate (Prysmian's <1% forecast error rate sets the bar for enterprise-grade forecasting)
Business outcome metrics:
- Fraud loss reduction (dollar value, not just detection rate)
- Default rate change by cohort
- Churn rate decrease and retention lift
- Forecast accuracy vs. actuals, and reduction in manual treasury hours
None of these metrics mean much without a reference point. Establish baselines before deployment — ideally 90+ days of pre-model actuals across each KPI you plan to track.
Without that benchmark, there's no way to attribute improvements to the model rather than external factors. You also lose the credibility that comes from showing investors or board stakeholders a clear before-and-after comparison when ROI questions arise.
Frequently Asked Questions
What is predictive analytics in finance?
Predictive analytics in finance uses machine learning and historical data to forecast future outcomes (fraud, credit defaults, customer churn, cash flow positions) before they occur. It shifts financial institutions from reactive reporting to proactive decision-making at scale.
What are the three different types of predictive analytics?
The three core model types are: time series models (trend forecasting over time), classification models (fraud vs. legitimate transactions), and cluster analysis (grouping customers by behavioral patterns). Complex fintech applications typically combine all three.
What is data analytics used for in fintech?
Core applications span fraud detection, credit risk assessment, churn prediction, cash flow forecasting, product recommendations, and compliance monitoring. Each use case maps to a distinct model type and data architecture.
What is predictive customer analytics?
Predictive customer analytics uses behavioral data (transaction history, app engagement, support contact frequency) to forecast individual customer actions like churn, product adoption, or payment default. The goal is enabling targeted interventions before those outcomes occur.
Which companies use predictive analytics?
Large institutions like HSBC (AML detection), JP Morgan (cash flow forecasting), and Revolut and Stripe (payment fraud) are well-documented adopters. Adoption is now expanding to mid-market fintechs and SMB platforms, with tools like QuickBooks and Xero shipping predictive cash flow features as standard.
What are the 4 types of business analytics?
Descriptive (what happened), diagnostic (why it happened), predictive (what will happen), and prescriptive (what action should be taken). Fintech companies that move into predictive and prescriptive tiers can act on risk signals before they materialize, rather than explaining losses after the fact.