
My Takeaways from Snowflake Summit 2025: A Faster, Cheaper, and More Open Data Cloud is Here
Just back from a whirlwind week at Snowflake Summit 2025, and my head is still spinning with the sheer volume of announcements. Cutting through the noise, the message was clear: Snowflake is aggressively evolving to be faster, more cost-effective, smarter, and more open than ever before. For those of us in the data analytics world, this isn't just a series of feature updates; it's a fundamental shift in what's possible.
Here is a deeper dive into the developments that stood out most to me and what they mean for the future of our work.
☃️ The New Economics: Faster Performance, Smarter Spending
Two announcements stood out as a powerful one-two punch for performance and cost optimization, directly addressing the core concerns of any data-driven organization.
First, the new Gen2 Warehouse (now generally available) promises a staggering 2.1x faster analytics performance. This isn't just marketing speak; it's a tangible leap forward driven by serious hardware and software upgrades. Under the hood, Gen2 warehouses leverage next-generation processors (like AWS Graviton3) with wider SIMD lanes and significantly more memory bandwidth. In practical terms, this means core database operations like columnar scans, joins, and aggregations chew through data much faster. For data teams, this translates to quicker insights and more productive development cycles.
But raw power can be expensive if not managed properly. That’s where Snowflake Adaptive Compute (in private preview) comes in. This is Snowflake's answer to the perpetual headache of resource management. The service intelligently and automatically selects the appropriate cluster size, number of clusters, and auto-suspend/resume duration for your jobs. It abstracts away the complex decision-making process, promising to deliver optimal price-performance without manual tuning. For anyone who has meticulously tried to right-size warehouses to balance performance and budget, this is a huge deal. It promises to make Snowflake a bit less expensive 😉 and a lot less effort to manage, which is always welcome news.
🏔️ Breaking Down Walls: Openness and Interoperability Take Center Stage
For years, the dream has been seamless interoperability without constantly moving and duplicating data. Snowflake is making massive strides to turn this into a reality, signaling a strong commitment to open standards.
Catalog Linked Databases (soon in public preview) are a game-changer for working with Apache Iceberg tables. These are essentially "shortcuts" that allow you to read from and write to any Iceberg table, no matter where it lives, without copying the data into Snowflake. The keynote demo was mind-blowing: they showed a data warehouse in Snowflake being hosted in Microsoft Fabric, with the ability to edit the data from either platform while the changes are reflected in both. This enables a true open lakehouse architecture where governance can be centralized in Snowflake even as data lives across a multi-cloud, multi-platform ecosystem. This is the end of data silos as we know them.
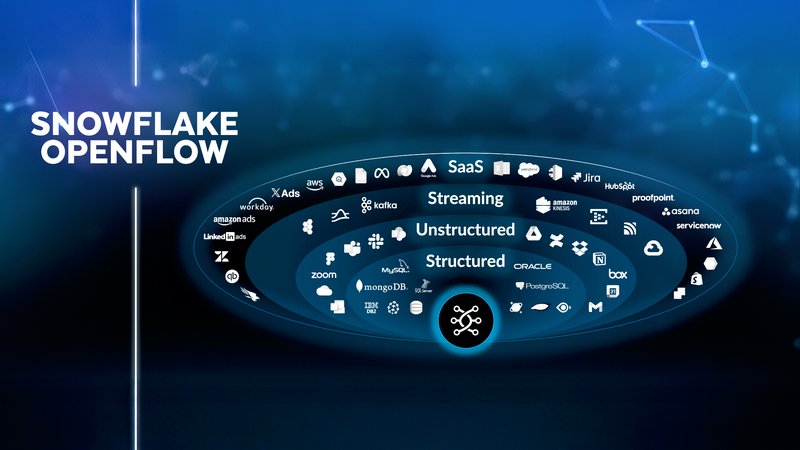
On the ingestion front, Snowflake Openflow (generally available on AWS) is poised to disrupt the tricky and expensive world of connectors. As an extensible, managed service powered by Apache NiFi, it simplifies data movement from a huge variety of sources. This isn't just about loading files; it’s about creating robust, observable, and declarative pipelines for batch and streaming data directly within Snowflake. Snowflake is aiming for 100 connectors by the end of the year, which puts it in direct competition with tools like Fivetran. The key advantages are native integration, reduced complexity, and a pricing model that consolidates costs into your Snowflake bill, eliminating the need to manage separate vendor contracts and infrastructure. This is one to watch closely.
❄️ The Intelligence Layer: Accessible AI Built on a Semantic Foundation
AI was everywhere at the Summit, but Snowflake's approach feels uniquely pragmatic, powerful, and built for the enterprise. The launch of Snowflake Intelligence (soon in public preview) introduces a new agentic AI platform that lets business users securely talk to their data in natural language.
The magic that makes this work reliably isn't just the Large Language Model (LLM); it's the Semantic Model. Snowflake placed a huge emphasis on this, and for good reason. By allowing you to define your business logic, KPIs, and metrics within Semantic Views, Snowflake ensures the AI gives consistent, accurate answers. It acts as a Rosetta Stone for your data, so when a user asks about "quarterly revenue," the AI knows precisely which tables, columns, and joins define that metric. This is a massive advantage over competitors like Google, where you often have to pay for a separate tool like Looker to create that crucial semantic layer.

Unpacking the Toolbox: A Closer Look at Cortex AISQL
While Snowflake Intelligence provides the conversational interface, Cortex AISQL (in public preview) provides the engine. It empowers analysts and developers by embedding generative AI capabilities directly into the SQL they write every day. This isn't just a minor add-on; it fundamentally changes what you can do inside a query.
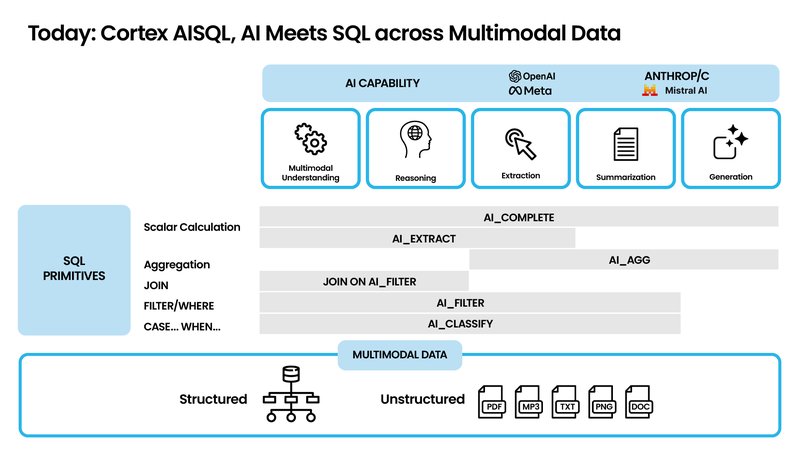
Let's break down what these powerful new functions actually do with some practical examples:
- AI_COMPLETE: This is your general-purpose generative function. You can ask it to summarize long text, rephrase content, or even generate creative copy based on structured data.
SELECT product_name, AI_COMPLETE(product_description, 'write a short, catchy marketing slogan') FROM products; - AI_EXTRACT: Perfect for pulling structured information from unstructured text. Think of extracting names, dates, or specific terms from a block of text like a customer email or a legal document.
SELECT AI_EXTRACT(email_body, 'the customer_name and order_number') FROM support_tickets; - AI_CLASSIFY: A powerful categorization tool. You can feed it text (or even images) and have it classify the content into predefined categories, like sorting support tickets into 'Urgent' and 'Standard' or identifying products in images.
SELECT review_text, AI_CLASSIFY(review_text, ['Positive', 'Negative', 'Neutral']) AS sentiment FROM customer_reviews; - AI_FILTER: This is semantic filtering, which goes beyond simple keyword matching. You can filter rows based on conceptual meaning.
SELECT complaint_text FROM support_tickets WHERE AI_FILTER(complaint_text, 'the user is upset about the product being damaged upon arrival'); - AI_AGG: This might be the most impressive. It allows you to aggregate insights across thousands of rows of text based on a prompt. Instead of a simple COUNT(), you can ask a complex question.
SELECT AI_AGG(feedback_text, 'What are the top 3 most common complaints?') FROM user_feedback;
These functions bring true multi-modal analysis (working with text, documents, and images) into a familiar SQL syntax. For data teams, this means radically faster development for AI-powered applications and a much lower barrier to entry for performing complex analysis that previously required specialized machine learning expertise.
🏂 For the Builders: The Snowflake dbt Experience
As a huge dbt fan, I was thrilled to see that dbt projects can now be created or imported directly into Snowflake workspaces for easy editing, testing, and deployment. This is a fantastic development for teams using dbt Core, streamlining their workflow significantly by bringing their transformation logic into the same environment as their data.
However, there's a small catch for dbt Cloud users. This new integration doesn't yet include dbt Cloud's new Fusion Engine. For context, the Fusion Engine is a ground-up rewrite of dbt that is much faster and more efficient, capable of parsing projects and providing real-time feedback in a way Python-based dbt Core cannot. It saves time and money by finding issues in the code before running it against the warehouse. The good news? During the platform keynote, it was mentioned that the Fusion Engine "will also come to the dbt project in some way." So while it’s a downside for now, the future looks very bright for a highly performant, integrated dbt experience within Snowflake.
Final Thoughts
This year's Summit felt different. The announcements weren't just about making Snowflake better; they were about fundamentally changing how we approach data work. The platform is rapidly becoming a unified, intelligent, and highly automated hub for not just analytics, but for AI development, application building, and open-format collaboration. By making the platform faster, more cost-efficient, more open, and deeply intelligent, Snowflake is empowering us to deliver more value than ever before. The future is connected, automated, and built on a semantic understanding of data—and it's happening now.
Ready to put these innovations to work? The new capabilities in Snowflake can transform your business, from optimizing costs to accelerating AI adoption. Contact us today to learn how we can help you leverage the power of the AI Data Cloud.
Diego Prinzi - Principal and Co-owner