
Your Data is Finally Ready to Talk Back. Building Semantic Models for AI Agents: A Layered Architecture
The argument in 60 seconds: For 20 years, dashboards were built for humans clicking dropdowns. Now AI agents are the primary consumer of your data, and they read your model differently than humans do. The fix isn't a new tool; it's separating your model into two layers, treating descriptions as load-bearing, and publishing a markdown companion that tells agents how to behave. Here's the architecture.
The Old Contract
For twenty years, the deal between a business user and their data team was simple: the data team builds the dashboard, the user clicks it. If the user wanted a different cut, they filed a ticket and waited.
That contract is dead. Users no longer want to click; they want to ask. And the thing they ask is not the data team. It's the agent sitting inside their browser, their inbox, their notebook, their phone.
The data team is no longer the consumer-facing surface. The agent is.
And if your data foundation was designed for a human clicking a dropdown, the agent is going to embarrass you.
The Monolith You Didn't Mean To Build
Most companies built their analytics stack as a single layer that tried to do everything at once: hold the business logic, look pretty, respond to specific report requests, govern access, and stay clean enough to trust. It never worked.
It produced what we'd now call a monolith: a semantic layer tangled in presentation logic. Disconnected tables built to let users switch measures on a Power BI chart. Calculated columns added for visual sorting. Time-intelligence wrappers baked into the core for one executive's preferred layout. A human analyst can squint at all of that and figure out what's going on. An AI agent cannot.
When an agent encounters a model bloated with dashboard workarounds, the predictable things happen: it wastes its context window on noise, misreads relationships, and hallucinates. Trust collapses on the first wrong number. If your model is optimized for a canvas layout instead of clean business logic, it's dead-on arrival in the agent era.
Two Layers, Two Different Jobs
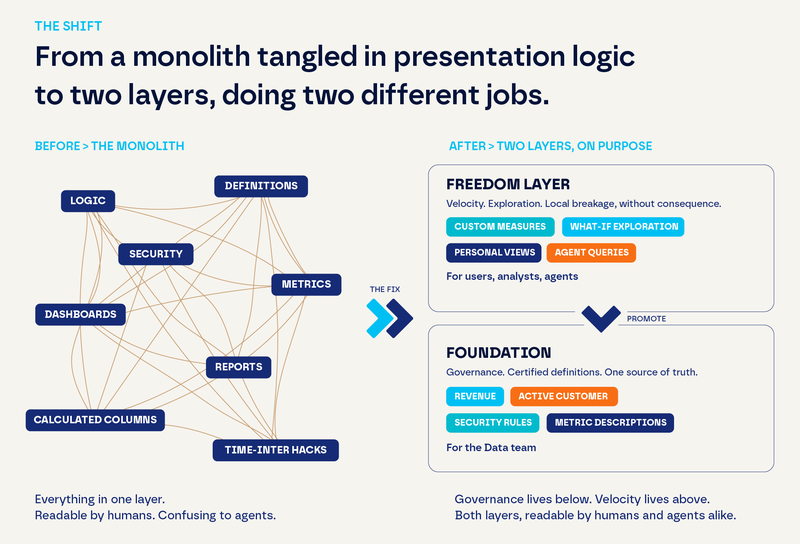
We think about it differently now. Two layers, doing two different jobs, on purpose.
The foundation, owned by the data team, locked down, certified. This is where the definitions of “revenue,” “active customer,” “year-over-year” live. There is one version of each, and that version is the version. If the foundation is wrong, you fix the foundation, and the fix reaches everyone at once. This layer is small, opinionated, and stripped of presentation junk — which is exactly what makes it readable to an agent. Tools like dbt and Looker were built for this layer.
The freedom layer, owned by the business user, the analyst, the agent. This is where someone takes the foundation and bends it to a specific question: a custom measure, a personal twist, a what-if. They explore. They break things, locally, without consequence. And when something they build turns out to be brilliant, there's a path to promote it up into the foundation.
This sounds like a small distinction, it isn't. The foundation is for governance, the freedom layer is for velocity. Trying to make one layer do both jobs is why everyone is exhausted.
What About Security?
The first objection from architects is the right one: if the freedom layer is open, what happens to row-level and object-level security?
Security doesn't live in either layer's UI. It lives in the foundation, and it travels with the data. When a downstream model inherits from the foundation — through a composite model in Power BI, a derived table in Looker, or a view in Snowflake — it inherits the access rules too. Agent, executive, or analyst, the same person gets the same answer they'd get anywhere else. You govern once. The rules apply everywhere.
The Thing No One Talks About
Here is the part almost no one is paying attention to, even though it may be the most important shift of the next two years.
When you build analytics on top of efficient architectures, the kind that read directly from your lake without moving data around, the kind that scale almost for free, you stop being able to hide complexity inside the model. The logic has to live cleanly upstream: in your warehouse, your aggregations, your transformation layer.
So, what's left in the model itself? The meaning. The names, the descriptions, the business rules in plain language, the warnings about edge cases.
For decades, those text boxes were the thing nobody filled in. Optional. A chore. The part you skipped because nobody read them.
They are now the most valuable real estate in your entire data stack.
Because the agent reads them. Every time. Standards like Anthropic's Model Context Protocol exist precisely so agents can read these descriptions reliably and act on them. The agent doesn't guess what is_active_customer means, it reads what you wrote. If you wrote nothing, it invents. If you wrote something vague, it interpolates. If you wrote something precise, it obeys.
The companies that win the next round of analytics won't be the ones with the fanciest models. They'll be the ones whose models are understood.
Beyond The Model: The Markdown Layer
There's a level above this that goes one step further, and it's where most of the value will live in 18 months.
Alongside the model, we now publish a companion document, written in plain language, structured for both humans and machines, that captures everything the schema alone cannot say. The business rules behind a metric. The questions this model is designed to answer well, and the ones it isn't. The warnings about what will silently produce wrong answers if ignored.
This isn't documentation in the boring sense. It's an operating manual for the agent: what to suggest, what to refuse, what to escalate, what to interpret strictly versus loosely.
A flag column says what. A description says what and why. The markdown layer says what, why, when, how, with whom, and what to avoid.
A Concrete, Real Example
A sales rep asks their agent: “How are we tracking this month?”.
In the old world, the agent would have summed a revenue field and given an answer. It would have been confidently wrong, because the field includes internal transfers, accounting reversals, and categories the finance team excludes from “real sales.”
In the new world, the agent reads the model, sees a metric called Revenue, reads the description, and learns this is the certified figure aligned with the company's official reporting. It uses that metric. The number matches what the CFO sees on their morning report.
The rep didn't have to know any of this. The trust came from the layer. That is the entire point.
How The Work Itself Changes
Five years ago, filling in the description field on every metric was a thankless chore nobody did. The cost was high, the benefit was zero, and nobody read those fields.
Today, the agent that helps you build the metric is the same agent that writes the description while you build it, and the same agent that consumes the description later. The marginal cost of documenting collapsed to almost nothing. The marginal value exploded.
It used to be expensive and pointless. Now it's free and essential. Most companies haven't noticed.
Where This Leaves You
The companies that will dominate analytics in the next cycle aren't the ones with the prettiest dashboards or the largest data lakes. They're the ones who have understood:
The foundation must be small, opinionated, and shared. The freedom layer must be open and experimental. Security has to live with the data, not the UI. The descriptions must be load-bearing. The markdown layer must exist. And the agent must be treated as the primary consumer the entire stack is being built for.
That's the architecture of analytics in the agent era.
It's not flashy. It's not a new tool. It's a posture, about which layer carries which responsibility, and about who you're really building for.
We're building for the agent. And so should you.
Dynamic Data is a boutique BI consultancy. We build foundations that humans, analysts, and agents can all stand on without falling through.
—
If you're staring at a model you suspect won't survive contact with an agent, we'd be glad to take a look. Send us a note at [email protected] or book a 20-minute call. No deck, no pitch, just a conversation about what you're actually trying to do.