
Data Stack Migration:
Overcoming Legacy Bottlenecks to Scale on Snowflake
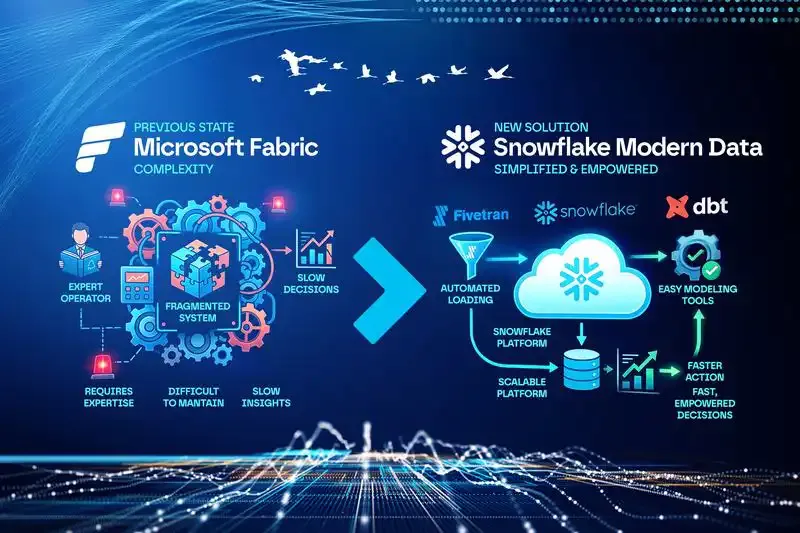
Unstructured was facing significant operational friction with its existing Microsoft Fabric infrastructure. Frequent pipeline execution errors, compute capacity limits that halted report loading, and unreliable native connectors had forced the team into highly manual, time-consuming data ingestion processes. To support their rapid organizational growth, they partnered with Dynamic Data to replace this setup with a highly stable, automated Snowflake environment.
Why Dynamic Data?

Multidisciplinary team that came together to offer a comprehensive service

A rare combination of
technical abilities and
interpersonal skills

Fully customized service,
adaptable to the
client's needs
About Unstructured
Industry: Information Technology & AI
Lines of business: Data Infrastructure and Analytics
Unstructured helps organizations extract and convert complex unstructured data from documents into AI-ready formats. To support their business analytics, they required a centralized, reliable data platform capable of being maintained without friction by a single-member data team.
The process
The goal
Execute a 100% accurate architectural overhaul in one month.
Dynamic Data replaced a complex infrastructure that was severely bottlenecking the company's data operations on a one-month timeline over the holiday season.
To succeed, the team had to resolve several deep operational blockers:
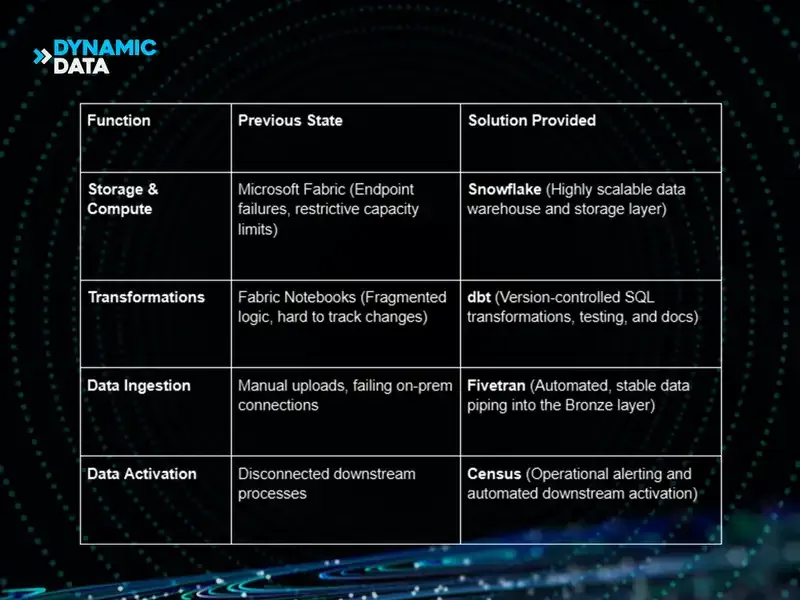
- Compute & Stability Issues: Fabric compute capacity limits, "out-of-sync" integrations, and SQL analytics endpoint failures were consistently disrupting daily reporting.
- Ingestion Bottlenecks: Unreliable API connections and failing native connectors meant marketplace data (AWS/Azure) and Postgres database dumps were heavily reliant on manual downloads and uploads.
- Complex Data Debt: Handling deeply nested JSON arrays from Cosmos DB required extensive, manual manipulation within Fabric notebooks that was difficult to version-control or scale.
"We had a very shortened timeframe for the project to be completed, and the team came through flawlessly."
Nicholas Pepera
The stack
To resolve these systemic issues, the migration completely replaced the Microsoft Fabric environment with a modern data stack centered around a Snowflake Medallion architecture. The team used Snowflake, dbt, Fivetran, and Census to execute the migration.
Standardizing Transformations and Ensuring Data Quality.
In the legacy Microsoft Fabric environment, Unstructured’s data transformations lacked standardization. Logic was fragmented, some scripts were written in Python, while others relied on SQL. This lack of uniformity meant that troubleshooting broken pipelines required advanced programming knowledge and deep historical context of the system. Furthermore, there were no automated data tests in place, leaving the system vulnerable to data quality issues.
By migrating the transformation layer to dbt, Dynamic Data standardized all data modeling exclusively into SQL. This strategic shift democratized the data stack: moving forward, any analyst with standard SQL knowledge can easily read, maintain, and update the pipelines without needing advanced Python expertise. To further solidify the new architecture, the team leveraged dbt’s native testing framework to configure rigorous, automated data tests, guaranteeing long-term data integrity and reliability.
Team Empowerment and Training.
Beyond just deploying the technology, Dynamic Data actively introduced Snowflake, Fivetran, and dbt to the Unstructured team. Through hands-on training and the delivery of highly detailed documentation, we empowered the client’s single-member data team to take full ownership of the modern stack, ensuring they could confidently navigate, troubleshoot, and scale the infrastructure independently.
The results
Successfully migrated the required pipelines, completely eliminating the compute limit failures experienced in the old environment.
Eradicated the need for manual data downloads by deploying fully automated, reliable ingestion workflows.
Delivered comprehensive system documentation and configured environments, enabling a smooth, immediate transition to the internal data team.
Successful deployment within the highly restrictive, shortened timeframe.

Nicholas Pepera